


Prior to understanding HAMTs, you’ll need to understand how hash tables and tries work. I already made a basic intro to hash tables which you can access here:
A great introduction and overview of what tries are is provided below:
A Hash Array Mapped Trie (HAMT) is a data structure that combines the benefits of hash tables and tries to efficiently store and retrieve key-value pairs. It is commonly used in computer science to implement associative arrays or dictionaries.
In a HAMT, keys are hashed to determine their storage location within an array, called a hash array. Each entry in the hash array can store multiple key-value pairs, allowing efficient memory utilization. If multiple keys hash to the same array index, a trie-like structure is used to resolve collisions.
Suppose we have a HAMT that stores words and their corresponding definitions. For simplicity, we’ll use a simple hash table that only has four slots for storing values and which we index using two bits.
Let’s say we want to store the following key-value pairs:
-
“apple” -> “a fruit”
-
“banana” -> “a tropical fruit”
-
“cat” -> “a small animal”
Initially, the HAMT is empty.
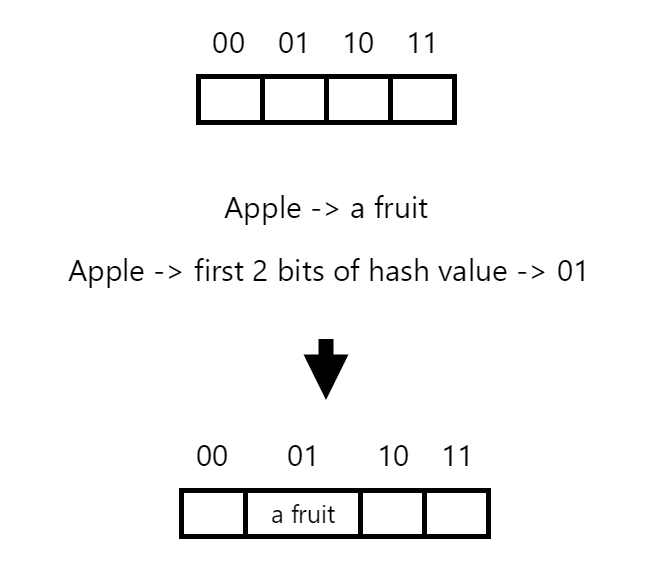
We start by inserting the first key-value pair, “apple” -> “a fruit”. The key “apple” is hashed, and the resulting index in the hash array is determined. Let’s assume that the hash for “apple” is composed of 32 bits, but we use the first 2 bits in order to find the correct index in our table. In this instance, let’s assume that the first 2 bits of our hash are 01. Since the array at the calculated index is empty, we store the key-value pair directly in that position.
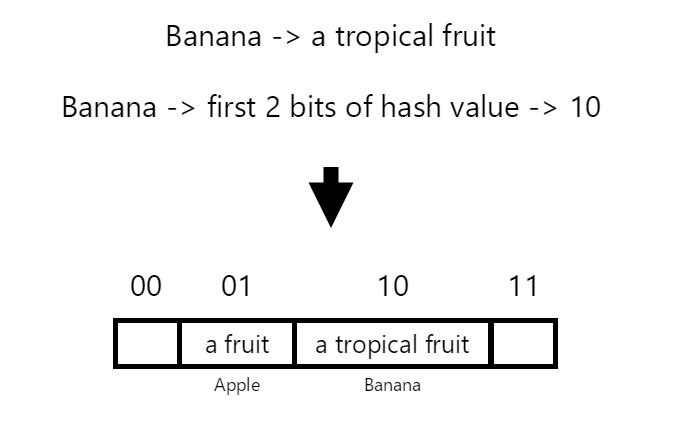
Next, we insert “banana” -> “a tropical fruit”.
Again, the key is hashed, and the corresponding index is found in the hash array. Let’s assume that the computed hash value for our key starts with 10. We can see that this index in our array is once again empty, so we once again store our value directly within the hash table:
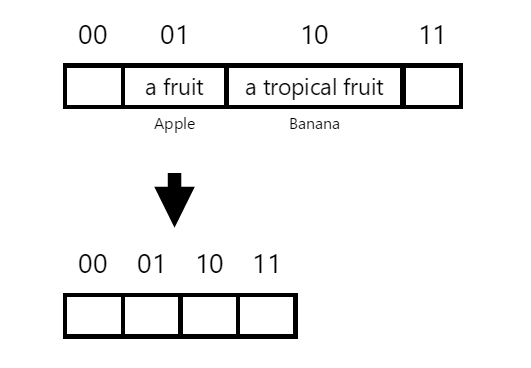
Finally, we insert “cat” -> “a small animal”. The key is hashed, and the corresponding index is determined. Let’s assume that the first 2 bits of the hashed value for cat turns out to once again be 01 (the same value that we used for apple). We now have a collision!!
Normally, when the hash table gets big, we need to allocate a larger and bigger hash table and recalculate all of our hash values. This can be a slow and expensive process! Is there any way that we can avoid having to perform this step?
Instead of performing a resize on our table, we simply allocate a new hash table (which also has 4 empty slots) and we link our collision slot (01) to point to this new table:
Now, we can add “cat” to our second table, but we have a slight problem. We need to use more bits in order to obtain our hash value. In this instance, we simply use the 1st 4 bits instead of just the 1st two (which we used for apple and banana).
Let’s assume that the first 4 bits of our hashed value for “cat” map to 0110. We already used the first 2 bits (01) to try to index our value in our first hash-table. Now, we use the next 2 bits (3