

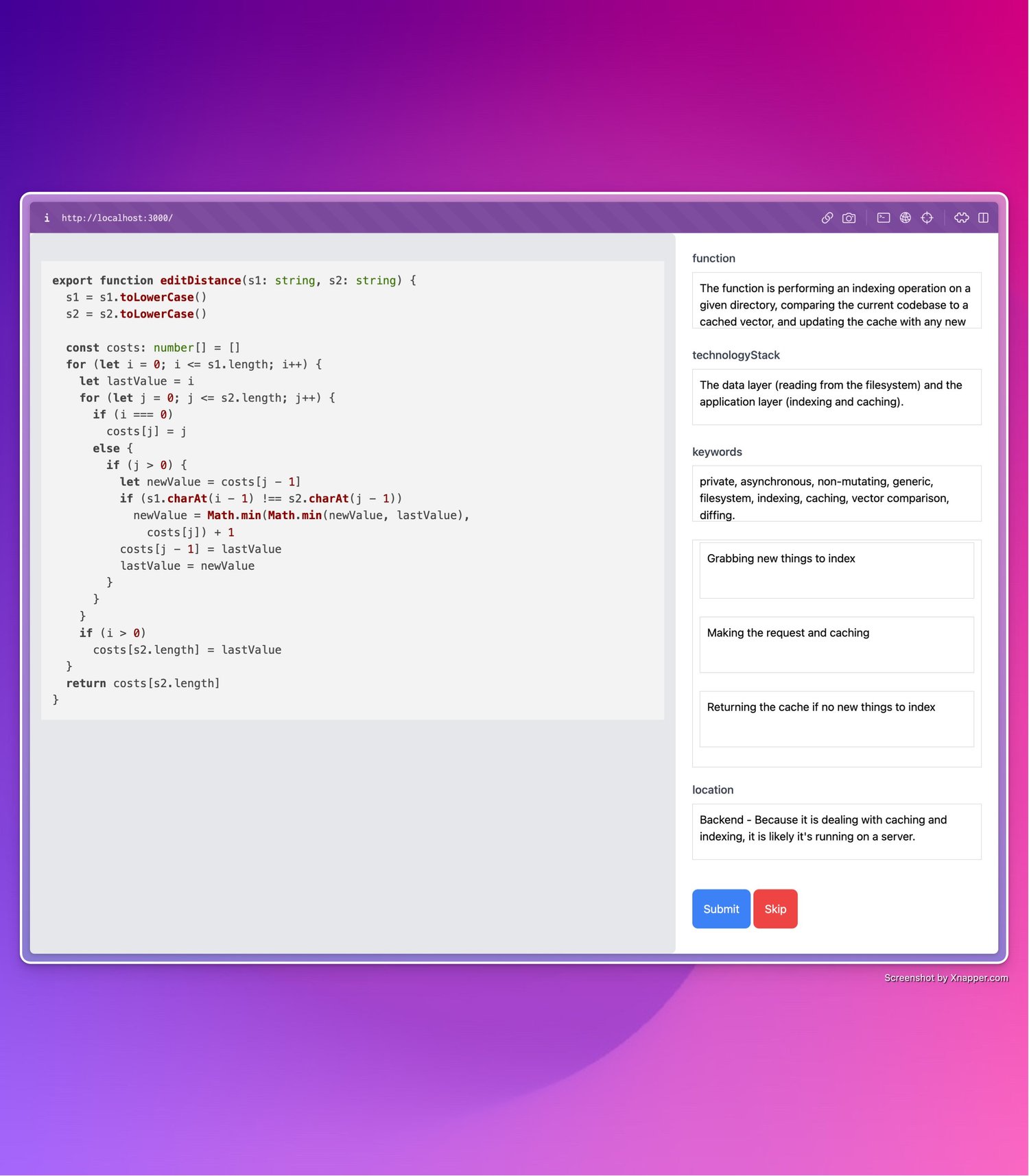

We’ve been using the OpenAI foundational models for a while now at Buildt, they are amazingly powerful and this has been well documented across the internet, particularly with the advent of ChatGPT which has garnered 100x more attention than GPT-3 did before it. However with these models, and their applications to our problem: codebase search, understanding and augmentation; we found an obvious barrier: latency and cost. The larger models (particularly the davinci family) obviously produce the highest quality outputs, but are the slowest and most expensive to run.
For a good search experience you need speed, this is clear when you see Google taking 100s of milliseconds to index millions of webpages, and the story is the same for codebase search. We found that one of the largest time draws on a single search was the LLM layer producing an output (we use LLMs to augment our search to allow you to search for what your code is rather than what it does, e.g. ‘find me my slowest recursive functions’). According to Alex Gravely, one of the creators of Github’s Copilot,