


Complicted SQL statements are some of the most common problems that data scientists and engineers encounter. For example, can you comprehend at first glance the complex SQL statement below?
select a.order_id,a.status,sum(b.money) as money from t_order a inner join (select c.order_id as order_id, c.number * d.price as money from t_order_detail c inner join t_order_price d on c.s_id = d.s_id) b on a.order_id = b.order_id where b.money > 100 group by a.order_id
How about formatting it? Is it easier to understand the formatted formatted version below?
SELECT a . order_id , a . status , SUM(b . money) AS moneyFROM t_order a INNER JOIN(SELECT c . order_id AS order_id, c . number * d . price AS moneyFROM t_order_detail c INNER JOIN t_order_price d ON c . s_id = d . s_id) b ON a . order_id = b . order_idWHEREb . money > 100GROUP BY a . order_id;
The first step to parse such a complex SQL is always formatting, and then its SQL semantics can be parsed based on the formatted content. SQL Formatter is, therefore, one of the essential functions of for any database software.
Accordingly, Apache ShardingSphere now offers a SQL formatting tool called SQL Parse Format that depends on ShardingSphere’s SQL dialect parser.
SQL Parse Format is an important function of the ShardingSphere Parser Engine, and also lays the foundation for ShardingSphere’s SQL Audit (TODO). This article offers a deep dive into the SQL Parse Format function:
- What’s its core concept?
- How you can use it?
- How can you develop SQL Parse Format?
To begin, we need to introduce more about Apache ShardingSphere’s Parser Engine because SQL Parse Format is a unique and relatively independent function of the parser engine.
Apache ShardingSphere developed the parser engine to extract key information in SQL, such as fields of data shards and rewritten columns for data encryption. So far, Apache ShardingSphere’s parser engine has undergone three iterations.
The initial parser engine leveraged Druid as its SQL parser and performed quite well before ShardingSphere Version 1.4.x.
Later the ShardingSphere community decided to develop its second-generation parser engine on its own. Since the use purpose was changed, ShardingSphere adopted another approach to comprehend SQL: only the contextual information that data sharding needs was extracted, without generating a parse tree or a secondary traversal, to improve performance and compatibility.
Currently, the third generation of ShardingSphere Parser Engine uses ANTLR as the parse tree generator and then extracts the contextual information by doing a secondary tree traversal. It is substantially compatible with more SQL dialects, which further accelerates developing other functions in Apache ShardingSphere.
In version 5.0.x, ShardingSphere developers further enhanced the performance of the newest parser engine by changing its tree traversal method from Listener to Visitor and adding parsing results cache for pre-compiled SQL statements.
The implementation of SQL Parse Format is attributable to the new parser engine. Next, let’s take a look at SQL Parse Format function.
SQL Parse Format is used to format SQL statements. Additionally, SQL Parse Format function will be used in SQL Audit in the future to provide users with viewing SQL history, displaying formatted SQL with reports, or further analyzing or processing SQL.
For instance, each part of the following SQL formatted by SQL Parse Format becomes clearer with wrapping and keywords in all caps:
select age as b, name as n from table1 join table2 where id = 1 and name = 'lu';
-- After Formatting
SELECT age AS b, name AS n
FROM table1 JOIN table2
WHERE
id = 1
and name = 'lu';
So far, we have covered the basics of the SQL Parse Format.
Next, let’s answer the question: what is the concept of SQL Parse Format?
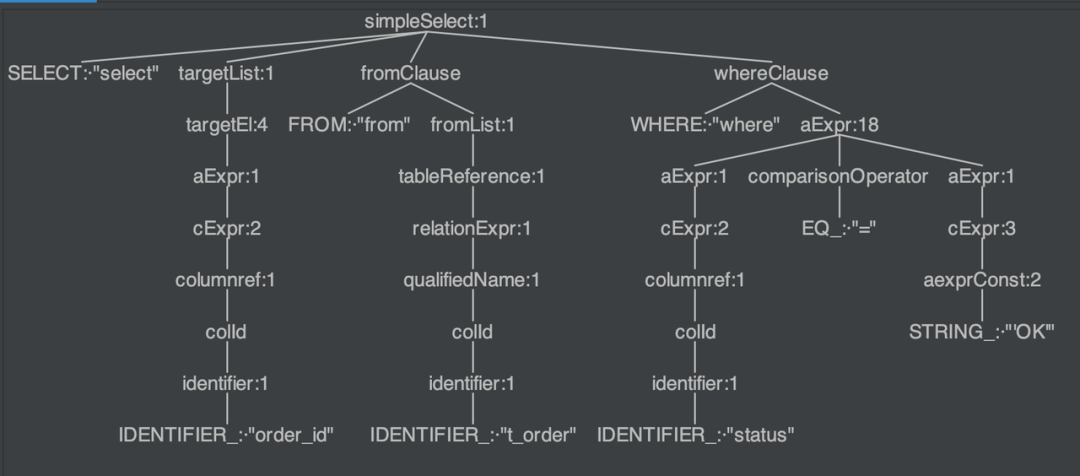
How a SQL statement is formatted in Apache ShardingSphere? Take the following SQL as an example:
select order_id from t_order where status = 'OK'
- Apache ShardingSphere uses
ANTLR4as its parser engine generator. First, we need to follow the ANTLR4 method to define the syntax ofselectin the.g4file (take MySQL as an example).
simpleSelect
: SELECT ALL? targetList? intoClause? fromClause? whereClause? groupClause? havingClause? windowClause?
| SELECT distinctClause targetList intoClause? fromClause? whereClause? groupClause? havingClause? windowClause?
| valuesClause
| TABLE relationExpr
;
2. We can use IDEA’s ANTLR4 plugin to easily view the syntax tree of the SQL statement.
For more information of ANTLR4 , please refer to: https://plugins.jetbrains.com/plugin/7358-antlr-v4.

ANTLR4 can compile the syntax file we define: it first performs lexical analysis on the SQL statement, splits it into indivisible parts, namely tokens, and divides these tokens into keywords, expressions, according to the dictionary values of different databases.
For example, in the image above, we get the keywords SELECT, FROM, WHERE, = and the variables order_id, t_order, status, OK.
3. Then ANTLR4 converts the output of the parser engine into the syntax tree as shown in the image above.
Based on the source code of Apache ShardingSphere, the above-mentioned process is reproduced as follows.
String sql = "select order_id from t_order where status = 'OK'";
CacheOption cacheOption = new CacheOption(128, 1024L, 4);
SQLParserEngine parserEngine = new SQLParserEngine("MySQL", cacheOption, false);
ParseContext parseContext = parserEngine.parse(sql, false);
4. The SQL Parser Engine of Apache ShardingSphere encapsulates and abstracts the ANTLR4 parser: it loads the SQL dialect parser through an SPI. Users can also extend data dialects through extension points of SPI. In addition, ShardingSphere adds a cache mechanism internally to improve performance. Take a look at the relevant code for parsing as follows:
public ParseContext parse(final String sql) {
ParseASTNode result = twoPhaseParse(sql);
if (result.getRootNode() instanceof ErrorNode) {
throw new SQLParsingException("Unsupported SQL of `%s`", sql);
}
return new ParseCo