

Welcome to VLM Run Hub, a comprehensive repository of pre-defined Pydantic schemas for extracting structured data from unstructured visual domains such as images, videos, and documents. Designed for Vision Language Models (VLMs) and optimized for real-world use cases, VLM Run Hub simplifies the integration of visual ETL into your workflows.
| Image | JSON |

|
{
"issuing_state": "MT",
"license_number": "0812319684104",
"first_name": "Brenda",
"middle_name": "Lynn",
"last_name": "Sample",
"address": {
"street": "123 MAIN STREET",
"city": "HELENA",
"state": "MT",
"zip_code": "59601"
},
"date_of_birth": "1968-08-04",
"gender": "F",
"height": "5'06"",
"weight": 150.0,
"eye_color": "BRO",
"issue_date": "2015-02-15",
"expiration_date": "2023-08-04",
"license_class": "D"
}
|
While vision models like OpenAI’s GPT-4o and Anthropic’s Claude Vision excel in exploratory tasks like “chat with images,” they often lack practicality for automation and integration, where strongly-typed, validated outputs are crucial.
The Structured Outputs API (popularized by GPT-4o, Gemini) addresses this by constraining LLMs to return data in precise, strongly-typed formats such as Pydantic models. This eliminates complex parsing and validation, ensuring outputs conform to expected types and structures. These schemas can be nested and include complex types like lists and dictionaries, enabling seamless integration with existing systems while leveraging the full capabilities of the model.
- 📚 Easy to use: Pydantic is a well-understood and battle-tested data model for structured data.
- 🔋 Batteries included: Each schema in this repo has been validated across real-world industry use cases—from healthcare to finance to media—saving you weeks of development effort.
- 🔍 Automatic Data-validation: Built-in Pydantic validation ensures your extracted data is clean, accurate, and reliable, reducing errors and simplifying downstream workflows.
- 🔌 Type-safety: With Pydantic’s type-safety and compatibility with tools like
mypyandpyright, you can build composable, modular systems that are robust and maintainable. - 🧰 Model-agnostic: Use the same schema with multiple VLM providers, no need to rewrite prompts for different VLMs.
- 🚀 Optimized for Visual ETL: Purpose-built for extracting structured data from images, videos, and documents, this repo bridges the gap between unstructured data and actionable insights.
The VLM Run Hub maintains a comprehensive catalog of all available schemas in the vlmrun/hub/catalog.yaml file. The catalog is automatically validated to ensure consistency and completeness of schema documentation. We refer the developer to the catalog-spec.yaml for the full YAML specification. Here are some featured schemas:
- Documents: document.bank-statement, document.invoice, document.receipt, document.resume, document.us-drivers-license, document.utility-bill, document.w2-form
- Other industry-specific schemas: healthcare.medical-insurance-card, retail.ecommerce-product-caption, media.tv-news, aerospace.remote-sensing
If you have a new schema you want to add to the catalog, please refer to the SCHEMA-GUIDELINES.md for the full guidelines.
Let’s say we want to extract invoice metadata from an invoice image. You can readily use our Invoice schema we have defined under vlmrun.hub.schemas.document.invoice and use it with any VLM of your choosing.
{kind=link}
For a comprehensive walkthrough of available schemas and their usage, check out our Schema Showcase Notebook.
import instructor from openai import OpenAI from vlmrun.hub.schemas.document.invoice import Invoice IMAGE_URL = "https://storage.googleapis.com/vlm-data-public-prod/hub/examples/document.invoice/invoice_1.jpg" client = instructor.from_openai( OpenAI(), mode=instructor.Mode.MD_JSON ) response = client.chat.completions.create( model="gpt-4o-mini", messages=[ { "role": "user", "content": [ {"type": "text", "text": "Extract the invoice in JSON."}, {"type": "image_url", "image_url": {"url": IMAGE_URL}, "detail": "auto"} ]} ], response_model=Invoice, temperature=0, )
JSON Response:
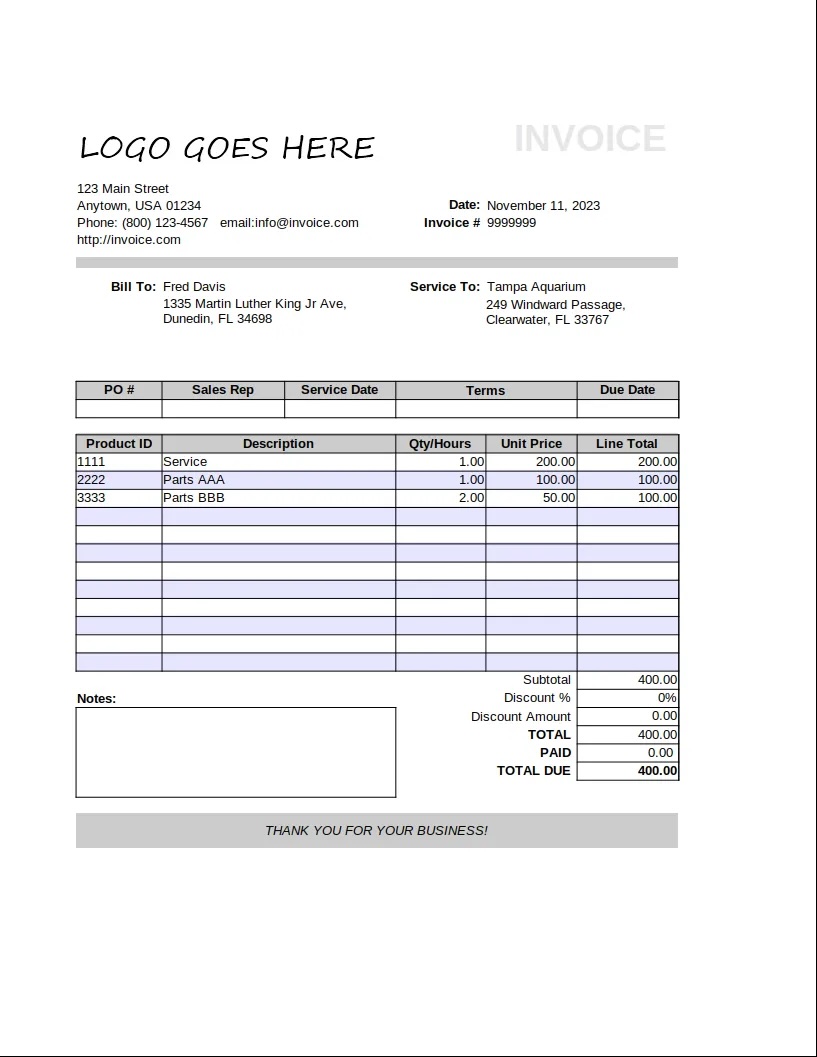
| Image | JSON Output 🔐 |
|
|
{
"invoice_id": "9999999",
"period_start": null,
"period_end": null,
"invoice_issue_date": "2023-11-11",
"invoice_due_date": null,
"order_id": null,
"customer_id": null,
"issuer": "Anytown, USA",
"issuer_address": {
"street": "123 Main Street",
"city": "Anytown",
"state": "USA",
"postal_code": "01234",
"country": null
},
"customer": "Fred Davis",
"customer_email": "email@invoice.com",
"customer_phone": "(800) 123-4567",
"customer_billing_address": {
"street": "1335 Martin Luther King Jr Ave",
"city": "Dunedin",
"state": "FL",
"postal_code": "34698",
"country": null
},
"customer_shipping_address": {
"street": "249 Windward Passage",
"city": "Clearwater",
"state": "FL",
"postal_code": "33767",
"country": null
},
"items": [
{
"description": "Service",
"quantity": 1,
"currency": null,
"unit_price": 200.0,
"total_price": 200.0
},
{
"description": "Parts AAA",
"quantity": 1,
"currency": null,
"unit_price": 100.0,
"total_price": 100.0
},
{
"description": "Parts BBB",
"quantity": 2,
"currency": null,
"unit_price": 50.0,
"total_price": 100.0
}
],
"subtotal": 400.0,
"tax": null,
"total": 400.0,
"currency": null,
"notes": "",
"others": null
}
|
json=json_data,
)” dir=”auto”>
import requests from vlmrun.hub.schemas.document.invoice import Invoice IMAGE_URL = "https://storage.googleapis.com/vlm-data-public-prod/hub/examples/document.invoice/invoice_1.jpg" json_data = { "image": IMAGE_URL, "model": "vlm-1", "domain": "document.invoice", "json_schema": Invoice.model_json_schema(), } response = requests.post( f"https://api.vlm.run/v1/image/generate", headers={"Authorization": f"Bearer" }, json=json_data, )
import instructor from openai import OpenAI from vlmrun.hub.schemas.document.invoice import Invoice IMAGE_URL = "https://storage.googleapis.com/vlm-data-public-prod/hub/examples/document.invoice/invoice_1.jpg" client = OpenAI() completion = client.beta.chat.completions.parse( model="gpt-4o-mini", messages=[ {"role": "user", "content": [ {"type": "text", "text": "Extract the invoice in JSON."}, {"type": "image_url", "image_url": {"url": IMAGE_URL}, "detail": "auto"} ]}, ], response_format=Invoice, temperature=0, )
When working with the OpenAI Structured Outputs API, you need to ensure that the
response_formatis a valid Pydantic model with the supported types.
Note: For certain vlmrun.common utilities, you will need to install our main Python SDK
via pip install vlmrun.
from ollama import chat from vlmrun.common.image import encode_image from vlmrun.common.utils import remote_image from vlmrun.hub.schemas.document.invoice import Invoice IMAGE_URL = "https://storage.googleapis.com/vlm-data-public-prod/hub/examples/document.invoice/invoice_1.jpg" img = remote_image(IMAGE_URL) chat_response = chat( model="llama3.2-vision:11b", format=Invoice.model_json_schema(), messages=[ { "role": "user", "content": "Extract the invoice in JSON.", "images": [encode_image(img, format="JPEG").split(",")[1]], }, ], options={ "temperature": 0 }, ) response = Invoice.model_validate_json( chat_response.message.content )
We periodically run popul
9 Comments
EarlyOom
We put together an open-source collection of Pydantic schemas for a variety of document categories (W2 filings, invoices etc.), including instructions for how to get structured JSON responses from any visual input with the model of your choosing. Run everything locally.
jbmsf
Interesting. We're using a SAAS solution for document extraction right now. I don't know if it's in our interest to build out more but I do like the idea of keeping extraction local.
jasonjmcghee
I've used "structured output" (with supplied schema) on Google and openai, and function calling / tool use on those, anthropic and others- and afaict they are functionally the same (if you force a specific function / schema). Has someone had a different experience?
kaushikbokka
Have you folks tried finetuning models for data extraction from visual data?
jauntywundrkind
I'd really like to play with Qwen2.5-VL at some point, perhaps for reading data-sheets for microchips. Nicely for some applications, it's also very good at reporting position of what it finds, which many ML tools are pretty mediocre at. https://qwenlm.github.io/blog/qwen2.5-vl/
Not really this application, but QvQ for visual reasoning is also impressive. https://qwenlm.github.io/blog/qvq-72b-preview/
Meta has used Qwen as the basis for their Apollo research. https://arxiv.org/abs/2412.10360
youknowwhentous
This seems to work for videos as well. Pretty cool demo and very nice interface for the pydantic types.
18chetanpatel
This is something I was searching for..Thanks for creating!
joatmon-snoo
Super cool! We at BAML had been thinking about doing something like this for our ecosystem as well – we’d love to add BAML models to this repo!
If you haven’t heard of us, we provide a language and runtime that enable defining your schemas in a simpler syntax, and allow usage with _any_ model, not just those that implement tool calling or json mode, by by relying on schema-aligned parsing. Check it out! https://github.com/BoundaryML/baml
Inviz
What are the most promising ways to extract information from picture like this, if the domain has strict time constraints? What's the second best way that is still fast?