swyx here: We’re proud to feature our first guest post of 2025! It has spawned great discussions on gdb, Ben, and Dan’s pages. See also our YouTube discussion.
We’ve been following Ben Hylak’s work on the Apple VisionOS for a bit, and invited him to speak at the World’s Fair. He has since launched Dawn Analytics, and continued to publish unfiltered thoughts about o1 — initially as a loud skeptic, and slowly becoming a daily user. We love mind-changers in both its meanings, and think this same conversation is happening all over the world as people struggle to move from the chat paradigm to the brave new world of reasoning and $x00/month prosumer AI products like Devin (spoke at WF, now GA). Here are our thoughts.
PSA: Due to overwhelming demand (>15x applications:slots), we are closing CFPs for AI Engineer Summit tomorrow. Last call! Thanks, we’ll be reaching out to all shortly!
How did I go from hating o1 to using it everyday for my most important questions?
I learned how to use it.
When o1 pro was announced, I subscribed without flinching. To justify the $200/mo price tag, it just has to provide 1-2 Engineer hours a month (the less we have to hire at dawn, the better!)
But at the end of a day filled with earnest attempts to get the model to work — I concluded that it was garbage.
Every time I asked a question, I had to wait 5 minutes only to be greeted with a massive wall of self-contradicting gobbledygook, complete with unrequested architecture diagrams + pro/con lists.
I tweeted as much and a lot of people agreed — but more interestingly to me, some disagreed vehemently. In fact, they were mind-blown by just how good it was.
Sure, people often get very hypey about OpenAI after launches (it’s the second best strategy to go viral, right after being negative.)
But this felt different — these takes were coming from folks deep in the trenches.
The more I started talking to people who disagreed with me, the more I realized I was getting it completely wrong:
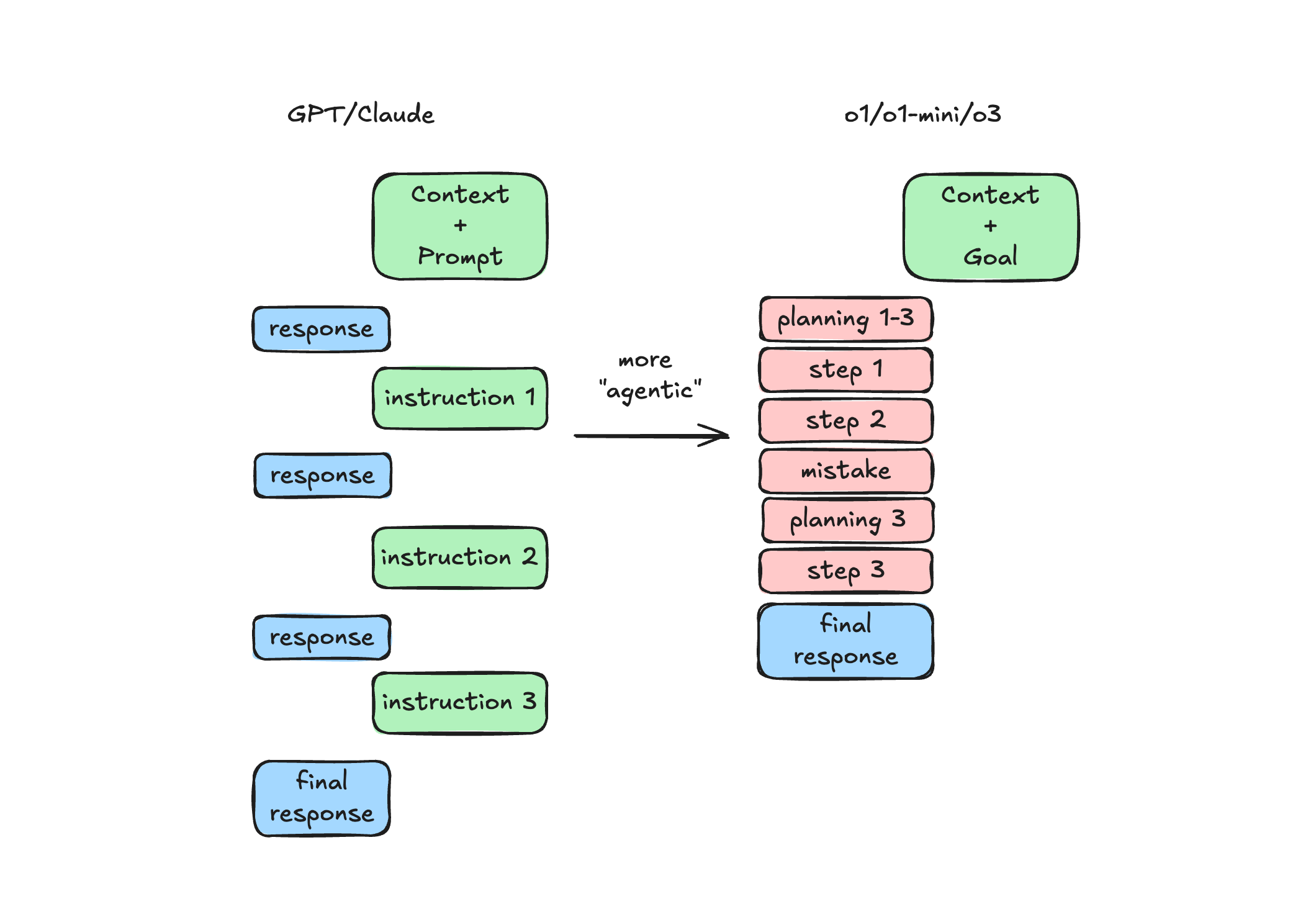
I was using o1 like a chat model — but o1 is not a chat model.
If o1 is not a chat model — what is it?
I think of it like a “report generator.” If you give it enough context, and tell it what you want outputted, it’ll often nail the solution in one-shot.
swyx’s Note: OpenAI does publish advice on prompting o1, but we find it incomplete, and in a sense you can view this article as a “Missing Manual” to lived experience using o1 and o1 pro in practice.
Give a ton of context. Whatever you think I mean by a “ton” — 10x that.
When you use a chat model like Claude 3.5 Sonnet or 4o, you often start with a simple question and some context. If the model needs more context, it’ll often ask you for it (or it’ll be obvious from the output).
(Putting context at the end is better for OpenAI models – per OpenAI’s own docs)
You iterate back and forth with the model, correcting it + expanding on requirements, until the desired output is achieved. It’s almost like pottery. The chat models essentially pull context from you via this back and forth. Overtime, our questions get quicker + lazier — as lazy as they can be while still getting a good output.
o1 will just take lazy questions at face value and doesn’t try to pull the context from you. Instead, you need to push as much context as you can into o1.
Even if you’re just asking a simple engineering question:
Explain everything that you’ve tried that didn’t work
Add a full dump of all your database schemas
Explain what your company does, how big it is (and define company-specific lingo)
In short, treat o1 like a new hire. Beware that o1’s mistakes include reasoning about how much it should reason.Sometimes the variance fails to accurately map to task difficulty. e.g. if the task is really simple, it will often spiral into reasoning rabbit holes for no reason. Note: the o1 API allows you to specify low/medium/high reasoning_effort, but that is not exposed to ChatGPT users.
Tips to make it easier giving o1 context
I suggest using the Voice Memos app on your mac/phone. I just describe the entire problem space for 1-2 minutes, and then paste that transcript in.
I actually have a note where I keep long segments of context to re-use.
The AI assistants that are popping up inside of products can often make this extraction easier. For example, if you use Supabase, try asking the Supabase Assistant to dump/describe all of the relevant tables/RPC’s/etc.
Once you’ve stuffed the model with as much context as possible — focus on explaining what you want the output to be.
With most models, we’ve been trained to tell the model how we want it to answer us. e.g.“You are an expert software engineer. Think slowly + carefully”
This is the opposite of how I’ve found success with o1. I don’t instruct it on the how — only the what. Then let o1 take over and plan and resolve its own steps. This is what the autonomous reasoning is for, and can actually be much faster than if you were to manually review and chat as the “human in the loop”.
swyx’s poor illustration attempt
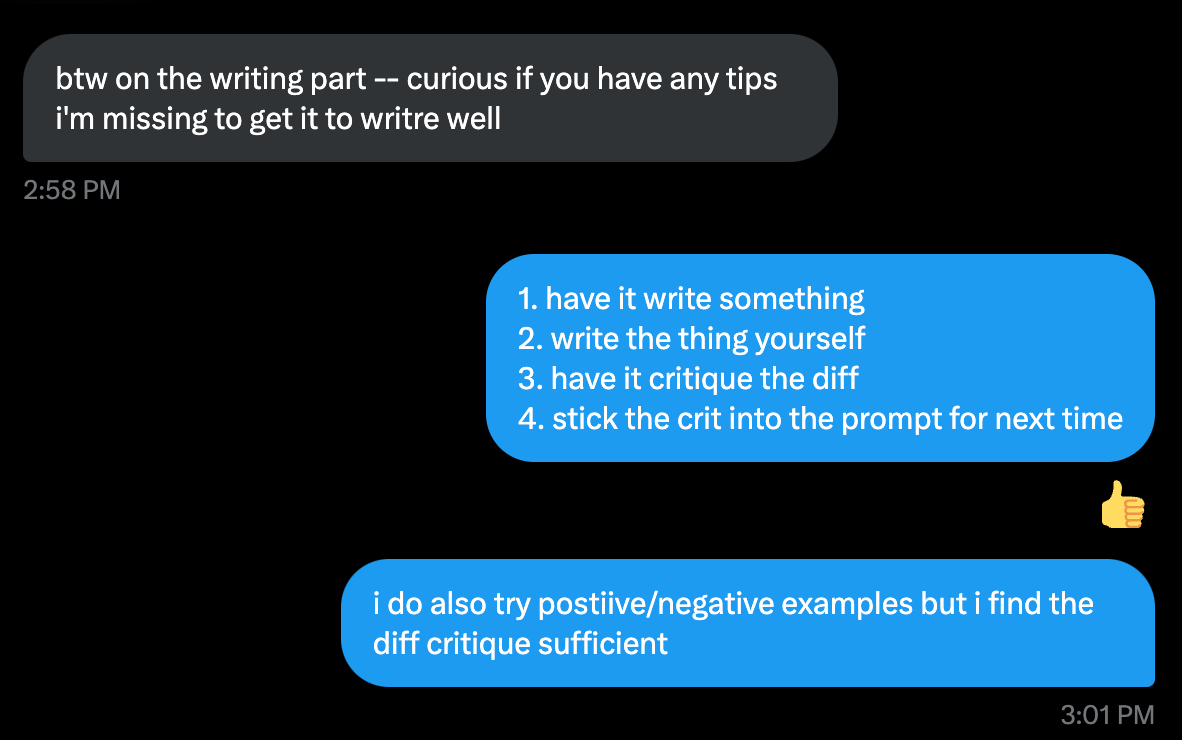
swyx’s pro tip: developing really good criteria for what you consider to be “good” vs “bad” helps you give the model a way to evaluate its own output and self-improve/fix its own mistakes. Essentially you’re moving the LLM-as-Judge into the prompt and letting o1 run it whenever needed.
As a bonus, this eventually gives you LLM-as-Judge evaluators you can use for Reinforcement Finetuning when it is GA.
This requires you to really know exactly what you want (and you should really ask for one specific output per prompt — it can only reason at the beginning!)
Sounds easier than it is! Did I want o1 to implement a specific architecture in production, create a minimal test app, or just explore options and list pros/cons? These are all
Whoops, you're not connected to Mailchimp. You need to enter a valid Mailchimp API key.
Our site uses cookies. Learn more about our use of cookies: cookie policyACCEPTREJECT
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.