

·
This post is an exploration of the supply and demand of GPUs, particularly Nvidia H100s. We’re also releasing a song and music video on the same day as this post.
Introduction #
As of July 2023, it seems AI might be bottlenecked by the supply of GPUs.
“One reason the AI boom is being underestimated is the GPU/TPU shortage. This shortage is causing all kinds of limits on product rollouts and model training but these are not visible. Instead all we see is Nvidia spiking in price. Things will accelerate once supply meets demand.”
— Adam D’Angelo, CEO of Quora, Poe.com, former Facebook CTO

{kind=link}
Is There Really A Bottleneck? #
Elon Musk says that “GPUs are at this point considerably harder to get than drugs.”1
Sam Altman says that OpenAI is GPU-limited and it’s delaying their short term plans (fine-tuning, dedicated capacity, 32k context windows, multimodality).2
Capacity of large scale H100 clusters at small and large cloud providers is running out.3
“Rn everybody wishes Nvidia could produce more A/H100”4
— Message from an exec at a cloud provider
“We’re so short on GPUs the less people use our products the better”
“We’d love it if they use it less because we don’t have enough GPUs”
Sam Altman, CEO at OpenAI5
It’s a good soundbite to remind the world how much users love your product, but it’s also true that OpenAI needs more GPUs.
For Azure/Microsoft:
- They are rate limiting employees on GPUs internally. They have to queue up like it was a university mainframe in the 1970s. I think OpenAI is sucking up all of it right now.
- The Coreweave deal is all about pasting on their GPU infrastructure.
— Anonymous
In short: Yes, there’s a supply shortage of H100 GPUs. I’m told that for companies seeking 100s or 1000s of H100s, Azure and GCP are effectively out of capacity, and AWS is close to being out.6
This “out of capacity” is based on the allocations that Nvidia gave them.
What do we want to know about the bottleneck?
- What’s causing it (how much demand, how much supply)
- How long will it last
- What’s going to help resolve it
The GPU Song #
Uh… We’re also releasing a song on the same day as we’re releasing this post. It’s fire.
If you haven’t heard The GPU Song yet, do yourself a favor and play it.
It’s on Spotify, Apple Music and YouTube.
See more info on the song here.
Table Of Contents #
- Introduction
- Table Of Contents
- Demand For H100 GPUs
- Who Needs H100s?
- Which GPUs Do People Need?
- What’s The Most Common Need From LLM Startups?
- What Do Companies Want For LLM Training And Inference?
- What Is Important For LLM Training?
- What Are The Other Costs Of Training And Running LLMs?
- What About GPUDirect?
- What Stops LLM Companies From Using AMD GPUs?
- H100 Vs A100: How Much Faster Are H100s Than A100s?
- Is Everyone Going To Want To Upgrade From A100s To H100s?
- What’s The Difference Between H100s, GH200s, DGX GH200s, HGX H100s, And DGX H100s?
- How Much Do These GPUs Cost?
- How Many GPUs Are Needed?
- Summary: H100 Demand
- Supply Of H100 GPUs
- Who Makes The H100s?
- Can Nvidia Use Other Chip Fabs For H100 Production?
- How Do The Different TSMC Nodes Relate?
- Which TSMC Node Is The H100 Made On?
- Which TSMC Node Does The A100 Use?
- How Long In Advance Is Fab Capacity Normally Reserved?
- How Long Does Production Take (production, Packaging, Testing)?
- Where Are The Bottlenecks?
- H100 Memory
- What Else Is Used When Making GPUs?
- Who Makes The H100s?
- Outlook And Predictions
- Sourcing H100s
- Closing Thoughts
- Acknowledgements
Demand For H100 GPUs #
What’s causing the bottleneck – Demand
- Specifically, what do people want to buy that they can’t?
- How many of those GPUs do they need?
- Why can’t they use a different GPU?
- What are the different product names?
- Where do companies buy them and how much do they cost?
Who Needs H100s? #
“It seems like everyone and their dog is buying GPUs at this point”7
– Elon
Who Needs/Has 1,000+ H100 Or A100s #
- Startups training LLMs
- CSPs (Cloud Service Providers)
- The big 3: Azure, GCP, AWS
- The other public cloud: Oracle
- Larger private clouds like CoreWeave, Lambda
- Other large companies
Who Needs/Has 100+ H100 Or A100s #
Startups doing significant fine-tuning large open source models.
What Are Most Of The High End GPUs Being Used For? #
For companies using private clouds (CoreWeave, Lambda), of companies with hundreds or thousands of H100s, it’s almost all LLMs, and some diffusion model work. Some of it is fine-tuning of existing models, but mostly it’s new startups that you may not yet know about that are building new models from scratch. They’re doing $10mm-50mm contracts done over 3 years, with a few hundred to a few thousand GPUs.
For companies using on-demand H100s with a handful of GPUs, it’s still probably >50% LLM related usage.
Private clouds are now starting to see inbound demand from enterprises who would normally be going with their default big cloud provider, but everyone is out.
Are The Big AI Labs More Constrained On Inference Or Training? #
Depends on how much product traction they have! Sam Altman says OpenAI would rather have more inference capacity if forced to choose, but OpenAI is still constrained on both.11
Which GPUs Do People Need? #
Mostly H100s. Why? It’s the fastest both for inference and training for LLMs. (The H100 is often also the best price-performance ratio for inference, too)
Specifically: 8-GPU HGX H100 SXM servers.
My analysis is it’s cheaper to run for the same work as well. The V100 a great deal if you could find them used, which you can’t
– Anonymous
honestly not sure about [it being the best price-performance ratio]? price/performance for training looks about the same for A100 as for H100. for inference, we find that A10Gs are more than enough and much cheaper.
– Private cloud exec
this [A10G’s being more than enough] was true for a while. but in the world of falcon 40b and llama2 70b, which we’re seeing a lot of usage for, it’s not true anymore. we need A100s for these
2xA100s to be exact. so the interconnect speed matters for inference.
– (Different) Private cloud exec
What’s The Most Common Need From LLM Startups? #
For training LLMs: H100s with 3.2Tb/s InfiniBand.
What Do Companies Want For LLM Training And Inference? #
For training they tend to want H100s, for inference it’s much more about performance per dollar.
It’s still a performance per dollar question with H100s vs A100s, but H100s are generally favored as they can scale better with higher numbers of GPUs and give faster training times, and speed / compressing time to launch or train or improve models is critical for startups.
“For multi-node training, all of them are asking for A100 or H100 with InfiniBand networking. Only non A/H100 request we see are for inference where workloads are single GPU or single node”
– Private cloud exec
What Is Important For LLM Training? #
- Memory bandwidth
- FLOPS (tensor cores or equivalent matrix multiplication units)
- Caches and cache latencies
- Additional features like FP8 compute
- Compute performance (related to number of cuda cores)
- Interconnect speed (eg InfiniBand)
The H100 is preferred over A100 partly because of things like lower cache latencies and FP8 compute.
H100 is preferred because it is up to 3x more efficient, but the costs are only (1.5 – 2x). Combined with the overall system cost, H100 yields much more performance per dollar (if you look at system performance, probably 4-5x more performance per dollar).
— Deep learning researcher
What Are The Other Costs Of Training And Running LLMs? #
GPUs are the most expensive individual component, but there are other costs.
System RAM and NVMe SSDs are expensive.
InfiniBand networking is costly.
10-15% of total cost for running a cluster might go to power and hosting (electricity, cost of the datacenter building, cost of the land, staff) – roughly split between the two, can be 5-8% for power and 5-10% for other elements of hosting cost (land, building, staff).
It’s mostly networking and reliable datacenters. AWS is difficult to work with because of network limitations and unreliable hardware
— Deep learning researcher
What About GPUDirect? #
GPUDirect is not a critical requirement, but can be helpful.
I would not say it is supercritical, but it makes a difference in performance. I guess it depends on where your bottleneck is. For some architectures / software implementations, the bottleneck is not necessarily networking, but if it is GPUDirect can make a difference of 10-20%, and that are some pretty significant numbers for expensive training runs.
That being said, GPUDirect RDMA is now so ubiquitous that it goes almost without saying that it is supported. I think support is less strong for non-InfiniBand networking, but most GPU clusters optimized for neural network training have Infiniband networks / cards. A bigger factor for performance might be NVLink, since this is rarer than Infiniband, but it is also only critical if you have particular parallelization strategies.
So features like strong networking and GPUDirect allows you to be lazy and you can guarantee that naive software is better out of the box. But it is not a strict requirement if you care about cost or using infrastructure that you already have.
– Deep learning researcher
What Stops LLM Companies From Using AMD GPUs? #
Theoretically a company can buy a bunch of AMD GPUs, but it just takes time to get everything to work. That dev time (even if just 2 months) might mean being later to market than a competitor. So CUDA is NVIDIA’s moat right now.
– Private cloud exec
I suspect 2 months is off by an order of magnitude, it’s probably not a meaningful difference, see https://www.mosaicml.com/blog/amd-mi250
– ML Engineer
Who is going to take the risk of deplying 10,000 AMD GPUs or 10,000 random startup silicon chips? That’s almost a $300 million investment.
– Private cloud exec
MosaicML/MI250 – Has anyone asked AMD about availability? It doesn’t seem like AMD built many beyond what they needed for Frontier, and now TSMC CoWoS capacity is sucked up by Nvidia. MI250 may be a viable alternative but unavailable.
– Retired semiconductor industry professional
H100 Vs A100: How Much Faster Are H100s Than A100s? #
About 3.5x faster for 16-bit inference12 and about 2.3x faster for 16-bit training.13

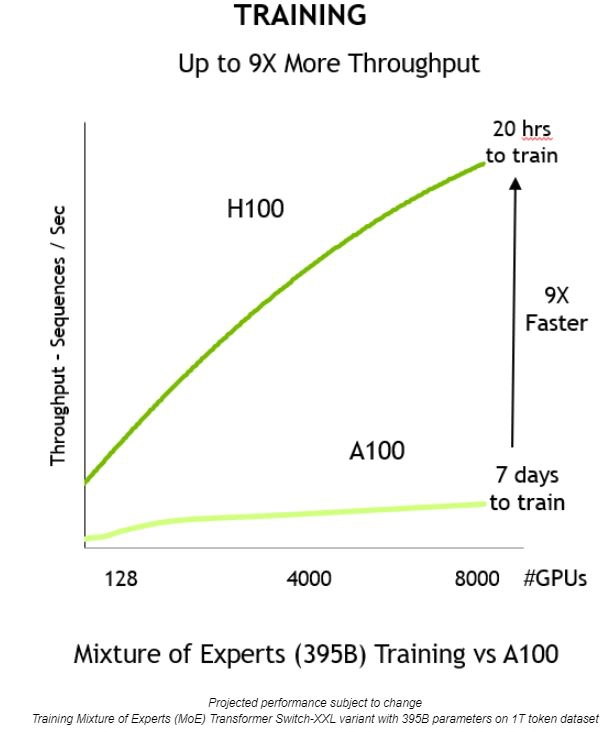

Here’s some more reading for you: 1 2 3.
Is Everyone Going To Want To Upgrade From A100s To H100s? #
Mostly people will want to buy H100s and use them for training and inference and switch their A100s to be used primarily for inference. But, some people might be hesitant to switch due to cost, capacity, the risk of using new hardware and setting it up, and their existing software being already optimized for A100s.
Yes, A100s will become today’s V100s in a few years. I don’t know of anyone training LLMs on V100s right now because of performance constraints. But they are still used in inference and other workloads. Similarly, A100 pricing will come down as more AI companies shift workloads to H100s, but there will always be demand, especially for inference.
– Private cloud exec
think it’s also plausible some of the startups that raised huge rounds end up folding and then there’s a lot of A100s coming back on the market
– (Different) Private cloud exec
Over time people will move and the A100s will be more used for inference.
What about V100s? Higher VRAM cards are better for large models, so cutting edge groups much prefer H100s or A100s.
The main reason for not using V100 is the lack of brainfloat16 (bfloat16, BF16) data type. Without that, its very difficult to train models easily. The poor performance of OPT and BLOOM can be mostly attributed to not having this data type (OPT was trained in float16, BLOOM’s prototyping was mostly done in fp16, which did not yield data was generalized to the training run which was done in bf16)
— Deep learning researcher
What’s The Difference Between H100s, GH200s, DGX GH200s, HGX H100s, And DGX H100s? #
- H100 = 1x H100 GPU
- HGX H100 = the Nvidia server reference platform that OEMs use to build 4-GPU or 8-GPU servers. Built by third-party OEMs like Supermicro.
- DGX H100 = the Nvidia official H100 server with 8x H100s.14 Nvidia is the sole vendor.
- GH200 = 1x H100 GPU plus 1x Grace CPU.15
- DGX GH200 = 256x GH200s,16 available toward the end of 2023.17 Likely only offered by Nvidia.
There’s also MGX which is aimed at large cloud companies.
Which Of Those Will Be Most Popular? #
Most companies will buy 8-GPU HGX H100s,18 rather than DGX H100s or 4-GPU HGX H100 servers.
How Much Do These GPUs Cost? #
1x DGX H100 (SXM) with 8x H100 GPUs is $460k including the required support. $100k of the $460k is required support. The specs are below. Startups can get the Inception discount which is about $50k off, and can be used on up to 8x DGX H100 boxes for a total of 64 H100s.
1x HGX H100 (SXM) with 8x H100 GPUs is between $300k-380k, depending on the specs (networking, storage, ram, CPUs) and the margins of whoever is selling it and the level of support. The higher end of that range, $360k-380k including support, is what you might expect for identical specs to a DGX H100.
1x HGX H100 (PCIe) with 8x H100 GPUs is approx $300k including support, depending on specs.
PCIe cards are around $30k-32k market prices.
SXM cards aren’t really sold as single cards, so it’s tough to give pricing there. Generally only sold as 4-GPU and 8-GPU servers.
Around 70-80% of the demand is for SXM H100s, the rest is for PCIe H100s. And the SXM portion of the demand is trending upwards, because PCIe cards were the only ones available for the first few months. Given most companies buy 8-GPU HGX H100s (SXM), the approximate spend is $360k-380k per 8 H100s, including other server components.
The DGX GH200 (which as a reminder, contains 256x GH200s, and each GH200 contains 1x H100 GPU and 1x Grace CPU) might cost in the range of $15mm-25mm – though this is a guess, not based on a pricing sheet.19
How Many GPUs Are Needed? #
- GPT-4 was likely trained on somewhere between 10,000 to 25,000 A100s.20
- Meta has about 21,000 A100s, Tesla has about 7,000 A100s, and Stability AI has about 5,000 A100s.21
- Falcon-40B was trained on 384 A100s.22
- Inflection used 3,500 H100s for their GPT-3.5 equivalent model.23
GPT-5 might need 30k-50k H100s according to Elon. Morgan Stanley said in Feb 2023 that GPT-5 would use 25,000 GPUs, but they also said it was already being trained as of Feb 2023 and Sam Altman said in May 2023 that it’s not yet being trained, so MS’s info may be outdated.
GCP has approx 25k H100s. Azure probably has 10k-40k H100s. Should be similar for Oracle. Most of Azure’s capacity is going to OpenAI.
CoreWeave is in the ballpark of 35k-40k H100s – not live, but based on bookings.
How Many H100s Are Most Startups Ordering? #
For LLMs: For fine tuning, dozens or low hundreds. For training, thousands.
How Many H100s Might Companies Be Wanting? #
OpenAI might want 50k