


TLDR: Many factors influence benchmarks for network-attached storage. Latency and throughput limitations, as well as protocol overhead, network congestion, and caching effects, may create much better or worse performance results than found in a real-world workload.
Benchmarking a storage solution, especially for network-attached storage, is supposed to provide us with a baseline for performance evaluation. You run the performance test, slap them into a dashboard, build a presentation, and that’s the basis for every further product evaluation.
What works great for local storage, where the SATA / SAS / PCI Express bus is your only foe, is more complicated when it comes to network-attached storage solutions (like NAS or SAN systems, NFS, Ceph, simplyblock, and similar alternatives). Benchmarking network storage quickly turns into an exercise of chasing ghosts, with multiple runs providing inconsistent results.
You’d think it’s pretty straightforward: you pick a tool (preferably fio), configure the workload, and hammer away on the storage target. But the catch is, network storage isn’t just a disk and a wire. It’s a full stack of components, from the server hardware (including the backing disks), the networking fabric (including switches, the wires, NICs), network protocols, and more.
All in all, benchmarking network storage is damn hard.
Let Your Network Lie to You
Modern networks are built to be robust and fault-tolerant. They are designed to provide reasonably consistent network performance. However, that wasn’t always the case, especially for Ethernet networks.
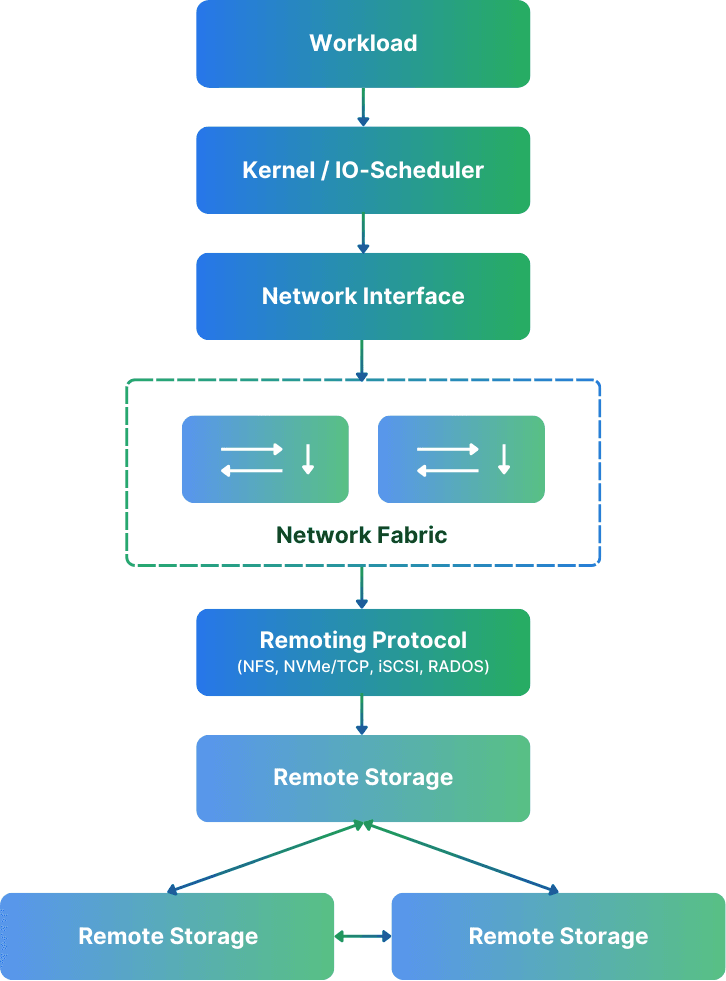
Fibre Channel and Infiniband were specialized storage networks designed to mitigate latency issues introduced in standard Ethernet networks. With higher bandwidth, these storage networks often provided better throughput, too. In recent years, however, Ethernet has just surpassed them. You can easily build a network with multiple 100G network cards, creating Tbit/s of throughput and enabling hundreds of millions of IOPS on a commodity Ethernet setup. Not even to talk about RDMA over Ethernet. If you ask me, a new storage network infrastructure should NEVER use any specialized Infiniband or Fibre Channel gear. Don’t waste your money!
Anyway, make sure you have a dedicated network for your storage traffic. Depending on the switches, a separate VLAN may be enough. Separate networks ensure as little congestion side effects (introduced by protocols such as TCP) as possible. In cloud environments, you also want to ensure that you use virtual machines (for client and servers) that offer dedicated network bandwidth. Up to means exactly how it sounds. You know how “up to” works for your internet connectivity, don’t you? 😀
For AWS, the easiest way to compare and find instances with dedicated network bandwidth is Vantage. I use it all the time. Just look for instances with a fixed number of bandwidth and no “up to.”
Also, ensure that your switches have enough switching bandwidth. Especially if you use core switches with multiple storage servers attached to them. Many clustered storage solutions, like simplyblock, have chatter and data traffic between storage nodes, not just your storage server and the client. Hence, you need to multiply the data traffic. A switch with insufficient or capped bandwidth may introduce unexpected performance bottlenecks.
Protocol Overhead – Not Just Latency but Complexity
Let’s say you’re testing NFS. On the surface, it’s just a shared filesystem, right? But under the hood, there’s a lot going on: stateless request/response semantics, per-operation metadata queries, and client-side caching behavior that can wildly distort results if not disabled.
Then look at Ceph. It’s no longer “just” a filesystem. You’re hitting one or more gateways (RADOS, NVMe/TCP) to talk to OSDs, which in turn map objects to placement groups. Possibly spread across replicated or erasure-coded pools. Every write will trigger multiple background operations, replication, recovery state, and rebalancing behavior.
Also, while simplyblock is easy to operate for the user, the internals aren’t as easy. Being fully built upon NVMe over Fabrics for internal and external cluster communication reduces the complexity and translation layers, though. Still, there is data and parity distribution for our distributed data placement, erasure coding, and the whole metadata subsystem handling. We aim to provide the most sensible defaults for NVMe/TCP, but there are plenty of options to bring into the system to achieve the theoretical maximum performance.
Each system has a different I/O path and different implications for performance under load. Understanding these differences and adjusting them accordingly is important when measuring a system’s performance.
Workload Fidelity: Your Benchmark Isn’t Realistic
Let’s be honest: most benchmarking setups are lazy. People grab fio, set a 4K random write workload with a queue depth of 32, and call it a day. And don’t believe most company-provided benchmarks are different.
The reason is simple. It’s extremely hard to create meaningful benchmarks with a mix of reads and writes that behave like the real world. Some databases have benchmarks that simulate a typical database workload (like TPC-C), but it’s still a simulation. It’s synthetic.
Real workloads aren’t uniform. Your databases are doing a mix of reads and wri