


In this post, we’ll implement a GPT from scratch in just 60 lines of numpy. We’ll then load the trained GPT-2 model weights released by OpenAI into our implementation and generate some text.
This post assumes familiarity with Python, NumPy, and some basic experience training neural networks. Code for this blog post can be found at github.com/jaymody/picoGPT.
What is a GPT?
GPT stands for Generative Pre-trained Transformer. It’s a type of neural network architecture based on the Transformer. Jay Alammar’s How GPT3 Works is an excellent introduction to GPTs at a high level, but here’s the tl;dr:
- Generative: A GPT generates text.
- Pre-trained: A GPT is trained on lots of text from books, the internet, etc …
- Transformer: A GPT is a decoder-only transformer neural network.
Large Language Models (LLMs) like OpenAI’s GPT-3 and Google’s LaMDA are just GPTs under the hood. What makes them special is they happen to be 1) very big (billions of parameters) and 2) trained on lots of data (hundreds of gigabytes of text).
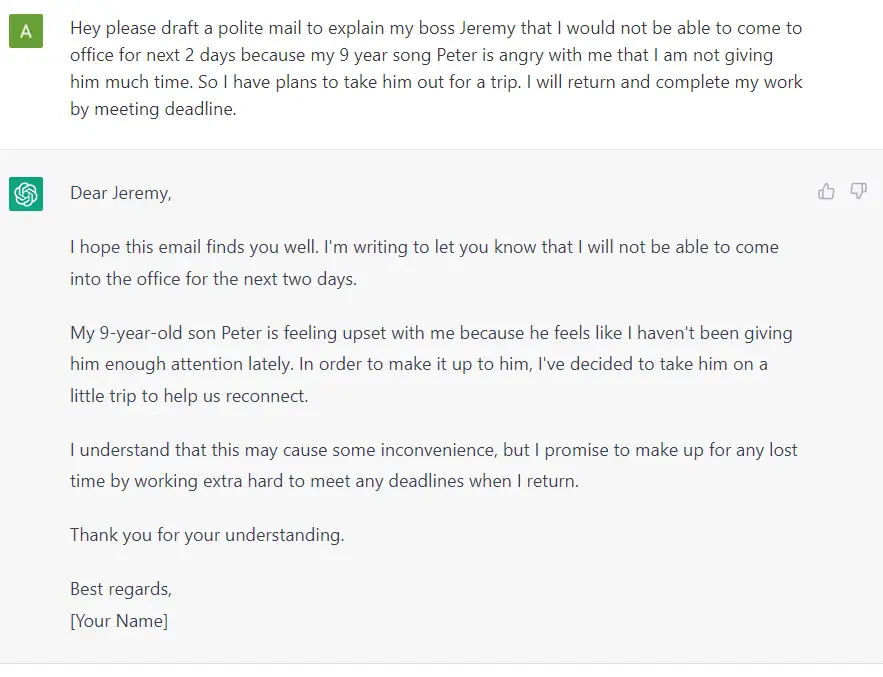
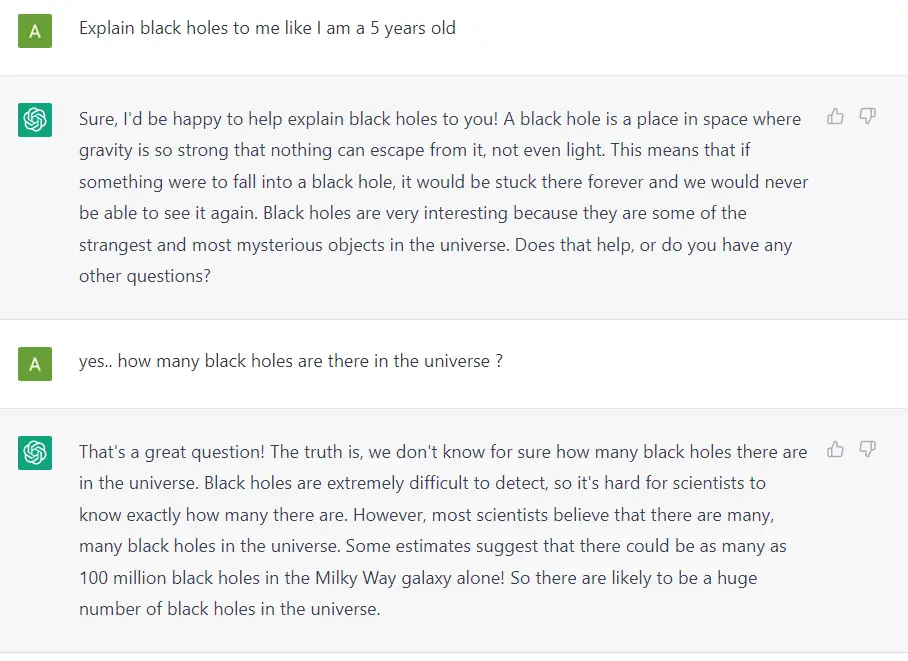
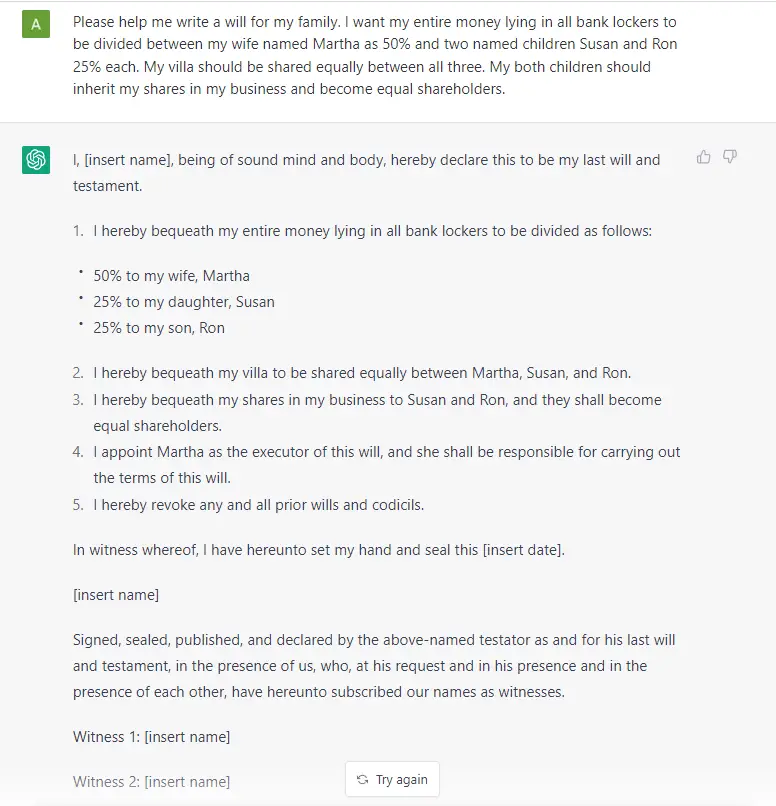
Fundamentally, a GPT generates text given a prompt. Even with this very simple API (input = text, output = text), a well trained GPT like ChatGPT can do some pretty awesome stuff like write your emails, summarize a book, give you instagram caption ideas, explain black holes to you as if you are 5 years old, code in SQL, and even write your will.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
So that’s a high-level overview of GPTs and their capabilities. Before we get into the fun architecture stuff, let’s just quickly recap:
- Input/Output
- Generating Text
- Training
Input / Output
The function signature for a GPT looks roughly like this:
def gpt(inputs: list[int]) -> list[list[float]]:
# inputs has shape [n_seq]
# output has shape [n_seq, n_vocab]
output = # beep boop neural network magic
return output
Input
The input is some text represented as sequence integers that represent string tokens:
# integers represent tokens in our text, for example:
# text = "not all heroes wear capes":
# tokens = "not" "all" "heroes" "wear" "capes"
inputs = [1, 0, 2, 4, 6]
These integer values come from the index of the tokens in a tokenizer‘s vocabulary, for example:
# the index of a token in the vocab represents the integer id for that token
# i.e. the integer id for "heroes" would be 2, since vocab[2] = "heroes"
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
# a pretend tokenizer that tokenizes on whitespace
tokenizer = WhitespaceTokenizer(vocab)
# the encode() method converts a str -> list[int]
ids = tokenizer.encode("not all heroes wear") # ids = [1, 0, 2, 4]
# we can see what the actual tokens are via our vocab mapping
tokens = [tokenizer.vocab[i] for i in ids] # tokens = ["not", "all", "heroes", "wear"]
# the decode() method converts back a list[int] -> str
text = tokenizer.decode(ids) # text = "not all heroes wear"
In short:
- We have a string.
- We use a tokenizer to break it down into smaller pieces called tokens.
- We use a vocabulary to map those tokens to integers.
In practice, we use more advanced methods of tokenization than simply splitting by whitespace, such as Byte-Pair Encoding or WordPiece, but the principle is the same:
- There is a
vocabthat maps string tokens to integer indices - There is an
encodemethod that convertsstr -> list[int] - There is a
decodemethod that convertslist[int] -> str
Output
The output is a 2D array, where output[i][j] is the model’s predicted probability that the token at vocab[j] is the next token inputs[i+1]. For example:
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[0] = [0.75 0.1 0.0 0.15 0.0 0.0 0.0 ]
# given just "not", the model predicts the word "all" with the highest probability
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[1] = [0.0 0.0 0.8 0.1 0.0 0.0 0.1 ]
# given the sequence ["not", "all"], the model predicts the word "heroes" with the highest probability
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[-1] = [0.0 0.0 0.0 0.1 0.0 0.05 0.85 ]
# given the whole sequence ["not", "all", "heroes", "wear"], the model predicts the word "capes" with the highest probability
To get our prediction for the next token for the whole sequence, we can simply take the token with the highest probability:
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
next_token_id = np.argmax(output[-1]) # next_token_id = 6
next_token = vocab[next_token_id] # next_token = "capes"
Taking the token with the highest probability as our final prediction is often referred to as greedy decoding or greedy sampling.
As such, a GPT is a language model, that is, it performs language modeling, the task of predicting the logical next word in a sequence.
Generating Text
Auto-Regressive
We can generate full sentences by iteratively asking our model the predict the next token. At each iteration, we append the predicted token back into the input:
def generate(inputs, n_tokens_to_generate):
for _ in range(n_tokens_to_generate): # auto-regressive decode loop
output = gpt(inputs) # model forward pass
next_id = np.argmax(output[-1]) # greedy sampling
inputs = np.append(out, [next_id]) # append prediction to input
return list(inputs[len(inputs) - n_tokens_to_generate :]) # only return generated ids
input_ids = [1, 0] # "not" "all"
output_ids = generate(input_ids, 3) # output_ids = [2, 4, 6]
output_tokens = [vocab[i] for i in output_ids] # "heroes" "wear" "capes"
This process of predicting a future value (regression), and adding it back into the input (auto) is why you might see a GPT described as auto-regressive.
Sampling
We can introduce some stochasticity (randomness) to our generations by sampling from the probability distribution instead of being greedy:
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
np.random.categorical(output[-1]) # capes
np.random.categorical(output[-1]) # hats
np.random.categorical(output[-1]) # capes
np.random.categorical(output[-1]) # capes
np.random.categorical(output[-1]) # pants
Not only does it allow us to generate different sentences for the same input, but it also increases the quality of the outputs compared to greedy decoding.
It’s also common to use techniques like top-k, top-p, and temperature to modify the probability distribution before sampling from it. This helps improve the quality of generations and also introduces hyper-parameters that we can play around with to get different generation behaviors (for example, increasing temperature makes our model take more risks and thus be more “creative”).
Training
We train a GPT like any other neural network, using gradient descent with respect to some loss function. In the case of a GPT, we take the cross entropy loss over the language modeling task:
def lm_loss(inputs: list[int]) -> float:
# the labels y are just the input shifted 1 to the left
#
# inputs = [not, all, heros, wear, capes]
# x = [not, all, heroes, wear]
# y = [all, heroes, wear, capes]
#
# of course, we don't have a label for inputs[-1], so we exclude it from x
#
# as such, for N inputs, we have N - 1 langauge modeling example pairs
x, y = inputs[:-1], inputs[1:]
# forward pass
# all the predicted next token probability distributions at each position
output = gpt(x)
# cross entropy loss
# we take the average over all N-1 examples
loss = np.mean(-np.log(output[y]))
return loss
def loss_fn(texts: list[list[str]]) -> float:
# take the mean of the language modeling losses over all
# text documents in our dataset
loss = 0
for text in texts:
inputs = tokenizer.encode(text)
loss += lm_loss(inputs)
return loss / len(texts)
Notice, we don’t need explicitly labelled data. Instead, we are able to produce the input/label pairs from just the raw text itself. This is referred to as self-supervised learning.
This means we can scale up train data really easily, we just throw as much text as we can get our hands on at at a GPT. For example, GPT-3 was trained on 300 billion tokens of text from the internet and books:
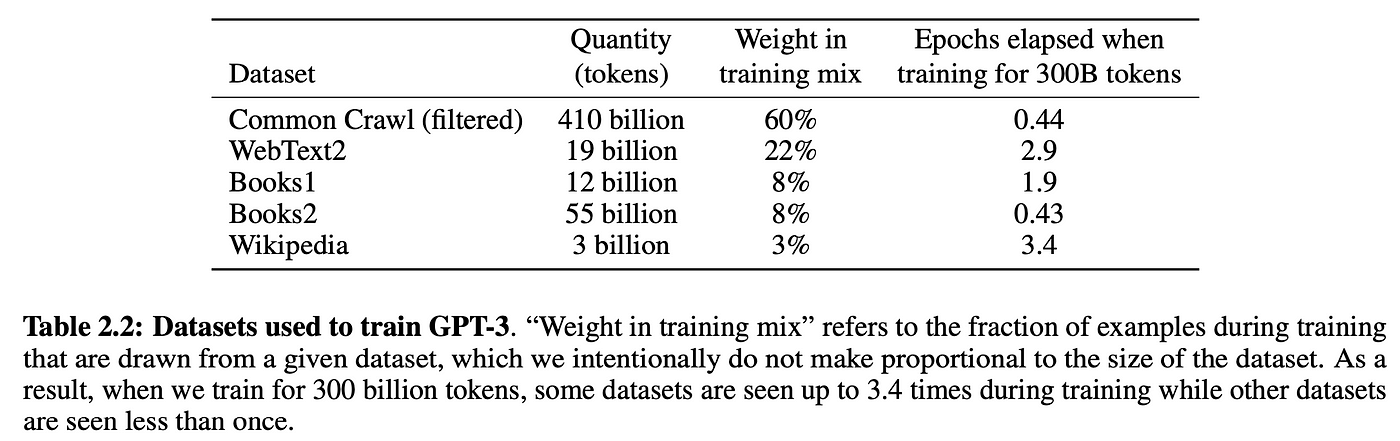
Of course, you need a sufficiently large model to be able to learn from all this data, which is why GPT-3 is 175 billion parameters and probably cost between $1m-10m in compute cost to train.
Setup
Clone the repository for this tutorial:
git clone https://github.com/jaymody/picoGPT
cd picoGPT
Then install dependencies:
pip install -r requirements.txt
Note, if you are using an M1 Macbook, you’ll need to change tensorflow to tensorflow-macos in requirements.txt before running pip install. This code was tested on Python 3.9.10.
A quick breakdown of each of the files:
encoder.pycontains the code for OpenAI’s BPE Tokenizer, taken straight from their gpt-2 repo.utils.pycontains the code to download and load the GPT-2 model weights, tokenizer, and hyper-parameters.gpt2.pycontains the actual GPT model and generation code which we can run as a python script.gpt2_pico.pyis the same asgpt2.py, but in even fewer lines of code (removed comments, extra whitespace, and combined certain operations into a single line). Why? Because why not.
We’ll be reimplementing gpt2.py from scratch, so let’s delete it and recreate it as an empty file:
rm gpt2.py
touch gpt2.py
As a starting point, paste the following code into gpt2.py:
import numpy as np
def gpt2(inputs, wte, wpe, blocks, ln_f, n_head):
pass # TODO: implement this
def generate(inputs, params, n_head, n_tokens_to_generate):
from tqdm import tqdm
for _ in tqdm(range(n_tokens_to_generate), "generating"): # auto-regressive decode loop
logits = gpt2(inputs, **params, n_head=n_head) # model forward pass
next_id = np.argmax(logits[-1]) # greedy sampling
inputs = np.append(inputs, [next_id]) # append prediction to input
return list(inputs[len(inputs) - n_tokens_to_generate :]) # only return generated ids
def main(prompt: str, n_tokens_to_generate: int = 40, model_size: str = "124M", models_dir: str = "models"):
from utils import load_encoder_hparams_and_params
# load encoder, hparams, and params from the released open-ai gpt-2 files
encoder, hparams, params = load_encoder_hparams_and_params(model_size, models_dir)
# encode the input string using the BPE tokenizer
input_ids = encoder.encode(prompt)
# make sure we are not surpassing the max sequence length of our model
assert len(input_ids) + n_tokens_to_generate < hparams["n_ctx"]
# generate output ids
output_ids = generate(input_ids, params, hparams["n_head"], n_tokens_to_generate)
# decode the ids back into a string
output_text = encoder.decode(output_ids)
return output_text
if __name__ == "__main__":
import fire
fire.Fire(main)
Breaking down each of the 4 sections:
- The
gpt2function is the actual GPT code we'll be implementing. You'll notice that the function signature, in addition toinputs, includes some extra stuff.wte,wpe,blocks, andln_fare parameters for our model,n_headis a hyper-parameter that is needed during the forward pass. - The
generatefunction is the auto-regressive decoding algorithm we saw earlier. We use greedy sampling instead of sampling from probabilities for simplicity and so we can get deterministic results.tqdmis a progress bar, so we can visualize the progress of our model as it generates tokens one at a time. - The
mainfunction handles:- Loading the tokenizer (
encoder), model weights (params), and hyper-parameters (hparams) - Encoding the input prompt into token ids using the tokenizer
- Calling the generate function
- Decoding the output ids into a string
- Loading the tokenizer (
fire.Fire(main)just turns the our file into a CLI application so we can eventually run our code with:python gpt2.py "some prompt here"
Let's take a closer look at encoder, hparams, and params, in a notebook, or an interactive python session, run:
from utils import load_encoder_hparams_and_params
encoder, hparams, params = load_encoder_hparams_and_params("124M", "models")
This will download the necessary model and tokenizer files to models/124M and load encoder, hparams, and params.
Encoder
encoder is the BPE tokenizer used by GPT-2. Here's an example of it encoding and decoding some text:
>>> ids = encoder.encode("Not all heroes wear capes.")
>>> ids
[3673, 477, 10281, 5806, 1451, 274, 13]
>>> encoder.decode(ids)
"Not all heroes wear capes."
Using the vocabulary of the tokenizer, we take also take a peek at what the actual tokens look like:
>>> [encoder.decoder[i] for i in ids]
['Not', 'Ġall', 'Ġheroes', 'Ġwear', 'Ġcap', 'es', '.']
Notice, sometimes our tokens are words (e.g. Not), sometimes they are words but with a space in front of them (e.g. Ġall, the Ġ represents a space), sometimes there are part of a word (e.g. capes is split into Ġcap and es), and sometimes they are punctuation (e.g. .).
One nice thing about BPE is that it can encode any arbitrary string. If it encounters something that is not present in the vocabulary, it just breaks it down into substrings it does understand:
>>> [encoder.decoder[i] for i in encoder.encode("zjqfl")]
['z', 'j', 'q', 'fl']
We can also check the size of the vocabulary:
>>> len(encoder.decoder)
50257
The vocabulary, as well as the byte-pair merges, are obtained by training the tokenizer. When we load the tokenizer, we're loading the already trained vocab and byte-pair merges from some files, which were downloaded alongside the model files when we ran load_encoder_hparams_and_params. See models/124M/encoder.json (the vocabulary) and models/124M/vocab.bpe (byte-pair merges).
Hyperparameters
hparams is a dictionary that contains the hyper-parameters of our model:
>>> hparams
{
"n_vocab": 50257, # number of tokens in our vocabulary
"n_ctx": 1024, # maximum possible sequence length of the input
"n_embd": 768, # embedding dimension (determines the "width" of the network)
"n_head": 12, # number of attention heads (n_embd must be divisible by n_head)
"n_layer": 12 # number of layers (determines t