I’ve just uploaded to the arXiv the paper “Decomposing a factorial into large factors“. This paper studies the quantity 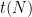 , defined as the largest quantity such that it is possible to factorize
, defined as the largest quantity such that it is possible to factorize  into
into  factors
factors  , each of which is at least . The first few values of this sequence are
, each of which is at least . The first few values of this sequence are

(OEIS A034258). For instance, we have  , because on the one hand we can factor
, because on the one hand we can factor

but on the other hand it is not possible to factorize 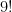 into nine factors, each of which is
into nine factors, each of which is  or higher.
or higher.
This quantity was introduced by Erdös, who asked for upper and lower bounds on ; informally, this asks how equitably one can split up into factors. When factoring an arbitrary number, this is essentially a variant of the notorious knapsack problem (after taking logarithms), but one can hope that the specific structure of the factorial can make this particular knapsack-type problem more tractable. Since

for any putative factorization, we obtain an upper bound

thanks to the Stirling approximation. At one point, Erdös, Selfridge, and Straus claimed that this upper bound was asymptotically sharp, in the sense that

as  ; informally, this means we can split into factors that are (mostly) approximately the same size, when is large. However, as reported in this later paper, Erdös “believed that Straus had written up our proof… Unfortunately Straus suddenly died and no trace was ever found of his notes. Furthermore, we never could reconstruct our proof, so our assertion now can be called only a conjecture”.
; informally, this means we can split into factors that are (mostly) approximately the same size, when is large. However, as reported in this later paper, Erdös “believed that Straus had written up our proof… Unfortunately Straus suddenly died and no trace was ever found of his notes. Furthermore, we never could reconstruct our proof, so our assertion now can be called only a conjecture”.
Some further exploration of was conducted by Guy and Selfridge. There is a simple construction that gives the lower bound

that comes from starting with the standard factorization  and transferring some powers of
and transferring some powers of  from the later part of the sequence to the earlier part to rebalance the terms somewhat. More precisely, if one removes one power of two from the even numbers between
from the later part of the sequence to the earlier part to rebalance the terms somewhat. More precisely, if one removes one power of two from the even numbers between  and , and one additional power of two from the multiples of four between
and , and one additional power of two from the multiples of four between  to , this frees up
to , this frees up  powers of two that one can then distribute amongst the numbers up to
powers of two that one can then distribute amongst the numbers up to  to bring them all up to at least
to bring them all up to at least  in size. A more complicated procedure involving transferring both powers of and
in size. A more complicated procedure involving transferring both powers of and  then gives the improvement
then gives the improvement  . At this point, however, things got more complicated, and the following conjectures were made by Guy and Selfridge:
. At this point, however, things got more complicated, and the following conjectures were made by Guy and Selfridge:
In this note we establish the bounds

as , where 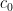 is the explicit constant
is the explicit constant

In particular this recovers the lost result (2). An upper bound of the shape

for some ![{c/>0}” src=”https://s0.wp.com/latex.php?latex=%7Bc%3E0%7D&bg=ffffff&fg=000000&s=0&c=20201002″ > was previously conjectured <a href=]() by Erdös and Graham (Erdös problem #391). We conjecture that the upper bound in (3) is sharp, thus
by Erdös and Graham (Erdös problem #391). We conjecture that the upper bound in (3) is sharp, thus

which is consistent with the above conjectures (i), (ii), (iii) of Guy and Selfridge, although numerically the convergence is somewhat slow.
The upper bound argument for (3) is simple enough that it could also be modified to establish the first conjecture (i) of Guy and Selfridge; in principle, (ii) and (iii) are now also reducible to a finite computation, but unfortunately the implied constants in the lower bound of (3) are too weak to make this directly feasible. However, it may be possible to now crowdsource the verification of (ii) and (iii) by supplying a suitable set of factorizations to cover medium sized , combined with some effective version of the lower bound argument that can establish  for all past a certain threshold. The value
for all past a certain threshold. The value  singled out by Guy and Selfridge appears to be quite a suitable test case: the constructions I tried fell just a little short of the conjectured threshold of
singled out by Guy and Selfridge appears to be quite a suitable test case: the constructions I tried fell just a little short of the conjectured threshold of  , but it seems barely within reach that a sufficiently efficient rearrangement of factors can work here.
, but it seems barely within reach that a sufficiently efficient rearrangement of factors can work here.
We now describe the proof of the upper and lower bound in (3). To improve upon the trivial upper bound (1), one can use the large prime factors of . Indeed, every prime  between
between  and divides at least once (and the ones between and
and divides at least once (and the ones between and 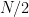 divide it twice), and any factor
divide it twice), and any factor  that contains such a factor therefore has to be significantly larger than the benchmark value of . This observation already readily leads to some upper bound of the shape (4) for some that are slightly less than (noting that any multiple of that exceeds , must in fact exceed
that contains such a factor therefore has to be significantly larger than the benchmark value of . This observation already readily leads to some upper bound of the shape (4) for some that are slightly less than (noting that any multiple of that exceeds , must in fact exceed  ) is what leads to the precise constant .
) is what leads to the precise constant .
For previous lower bound constructions, one started with the initial factorization  and then tried to “improve” this factorization by moving around some of the prime factors. For the lower bound in (3), we start instead with an approximate factorization roughly of the shape
and then tried to “improve” this factorization by moving around some of the prime factors. For the lower bound in (3), we start instead with an approximate factorization roughly of the shape

where  is the target lower bound (so, slightly smaller than ), and
is the target lower bound (so, slightly smaller than ), and  is a moderately sized natural number parameter (we will take
is a moderately sized natural number parameter (we will take  , although there is significant flexibility here). If we denote the right-hand side here by
, although there is significant flexibility here). If we denote the right-hand side here by  , then is basically a product of numbers of size at least . It is not literally equal to ; however, an easy application of Legendre’s formula shows that for odd small primes , and have almost exactly the same number of factors of . On the other hand, as is odd, contains no factors of , while contains about such factors. The prime factorizations of and differ somewhat at large primes, but has slightly more such prime factors as (about
, then is basically a product of numbers of size at least . It is not literally equal to ; however, an easy application of Legendre’s formula shows that for odd small primes , and have almost exactly the same number of factors of . On the other hand, as is odd, contains no factors of , while contains about such factors. The prime factorizations of and differ somewhat at large primes, but has slightly more such prime factors as (about  such factors, in fact). By some careful applications of the prime number theorem, one can tweak some of the large primes appearing in to make the prime factorization of and agree almost exactly, except that is missing most of the powers of in , while having some additional large prime factors beyond those contained in to compensate. With a suitable choice of threshold , one can then replace these excess large prime factors with powers of two to obtain a factorization of into terms that are all at least , giving the lower bound.
such factors, in fact). By some careful applications of the prime number theorem, one can tweak some of the large primes appearing in to make the prime factorization of and agree almost exactly, except that is missing most of the powers of in , while having some additional large prime factors beyond those contained in to compensate. With a suitable choice of threshold , one can then replace these excess large prime factors with powers of two to obtain a factorization of into terms that are all at least , giving the lower bound.
The general approach of first locating some approximate factorization of (where the approximation is in the “adelic” sense of having not just approximately the right magnitude, but also approximately the right number of factors of for various primes ), and then moving factors around to get an exact factorization of , looks promising for also resolving the conjectures (ii), (iii) mentioned above. For instance, I was numerically able to verify that  by the following procedure:
by the following procedure:
- Start with the approximate factorization of ,
 by
by  . Thus is the product of odd numbers, each of which is at least
. Thus is the product of odd numbers, each of which is at least  .
.
- Call an odd prime -heavy if it divides more often than , and -heavy if it divides more often than . It turns out that there are
 more -heavy primes than -heavy primes (counting multiplicity). On the other hand, contains
more -heavy primes than -heavy primes (counting multiplicity). On the other hand, contains  powers of , while has none. This represents the (multi-)set of primes one has to redistribute in order to convert a factorization of to a factorization of .
powers of , while has none. This represents the (multi-)set of primes one has to redistribute in order to convert a factorization of to a factorization of .
- Using a greedy algorithm, one can match a -heavy prime
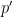 to each -heavy prime (counting multiplicity) in such a way that
to each -heavy prime (counting multiplicity) in such a way that  for a small
for a small  (in most cases one can make
(in most cases one can make  , and often one also has
, and often one also has  ). If we then replace in the factorization of by
). If we then replace in the factorization of by  for each -heavy prime , this increases (and does not decrease any of the factors of ), while eliminating all the -heavy primes. With a somewhat crude matching algorithm, I was able to do this using
for each -heavy prime , this increases (and does not decrease any of the factors of ), while eliminating all the -heavy primes. With a somewhat crude matching algorithm, I was able to do this using  of the
of the  powers of di
powers of di



8 Comments
Sharlin
[flagged]
btilly
Out of curiosity, I wondered how tight these bounds are. Consider the case of 300,000 which Terry has put a lower bound of 90,000 on, and would like a bound of 100,000 on. If a perfect division of factors into equal buckets could be achieved, the answer would be 110366.49020484093 per bucket. That's e^(log(n!)/n), to within the precision that Python calculates it. (My first try was to use Stirling's formula. That estimated it at 110366.49020476094, which is pretty darned close!)
A straightforward greedy approach will see those final buckets differing by factors of around 2. Which is a lot worse than Terry's current approach.
This really is a knapsack problem.
zahlman
From comments:
>No; in fact, in Guy’s article on this problem, he notes that there is a jump of 2 from t(124)=35 to t(125)=37
Huh. Can we actually prove t(N) is monotonic? Jumps like that seem like they could be one-offs in some cases.
curtisszmania
[dead]
tempodox
I'm still confused as to how to compute t(N). Maybe it's buried in the legalese of this text and I'm just dumb, but I can't find a clue.
SJC_Hacker
Edit: as pointed out, you can't simply divide by each number, because then its not equal to original number factorial. However, I've fixed the algorithm somewhat maintaining the basic idea
The "naive" way
Obviously t(100) > 1. If we can get rid of the single 2, we know that t(100) > 2. If you multiply the whole thing by 2/2 (=1),
We can continue with t(100) > 3 by multiplying by 3/3 and pairing it with 99, i.e. 99*3*(3/3) = (99/3)*3*3 = 33*9 yielding
However, once we get to t(100) > 4, trying to get rid of 4, we have to skip 98 since its not divisible by 4. The other problem is we have two 4s… If we had instead using 98 for getting rid of 2, we can then use 100, and 96 for the other 4. This is our first "gotcha" for the naive algorithm of always picking the largest number, which seems intuitive at first glance.
Now if we test all possibilities starting with 2, we get 48 choices for the dividing 2 (even numbers > 2, not including 2 which will not increase t(100) beyond 2. Then ~33 choices for dividing 3 (depending if our div of 2 resulted in a factor of 3), ~25 for 4, But notice since we now have two 4s, we have to do it twice, so its 25*24 choices for getting rid of 4.*
dvh
As a kid I was bugged by the fact that Stirling formula doesn't give exact integer result, so I set to find my own formula. I failed, but discovered that sum from 1 to N is (n*n+n)/2. Surely if perfect formula for sum exists, for multiplication should exist too.
phkahler
Is there a standard notation for the product of all even numbers up to N and for the product of all odd numbers up to N? I know if N is even then the product of evens is = (N/2)! * 2^(N/2) so I guess notation for that is a little redundant, but there is no simple formula for the product of the odd numbers.