

This is a fascinating time in the study and application of large language models. New advancements are announced every day!
In this guide, I share my analysis of the current architectural best practices for data-informed language model applications. This particular subdiscipline is experiencing phenomenal research interest even by the standards of large language models – in this guide, I cite 8 research papers and 4 software projects, with a median initial publication date of November 22nd, 2022.
Overview
In nearly all practical applications of large language models (LLM’s), there are instances in which you want the language model to generate an answer based on specific data, rather than supplying a generic answer based on the model’s training set. For example, a company chatbot should be able to reference specific articles on the corporate website, and an analysis tool for lawyers should be able to reference previous filings for the same case. The way in which this external data is introduced is a key design question.
At a high level, there are two primary methods for referencing specific data:
- Insert data as context in the model prompt, and direct the response to utilize that information
- Fine-tune a model, by providing hundreds or thousands of prompt <> completion pairs
Shortcomings of Knowledge Retrieval for Existing LLM’s
Both of these methods have significant shortcomings in isolation.
For the context-based approach:
- Models have a limited context size, with the latest `davinci-003` model only able to process up to 4,000 tokens in a single request. Many documents will not fit into this context.
- Processing more tokens equates to longer processing times. In customer-facing scenarios, this impairs the user experience.
- Processing more tokens equates to higher API costs, and may not lead to more accurate responses if the information in the context is not targeted.
For the fine-tuning approach:
- Generating prompt <> completion pairs is time-consuming and potentially expensive.
- Many repositories from which you want to reference information are quite large. For example, if your application is a study aid for medical students taking the US MLE, a comprehensive model would have to provide training examples across numerous disciplines.
- Some external data sources change quickly. For example, it is not optimal to retrain a customer support model based on a queue of open cases that turns over daily or weekly.
- Best practices around fine-tuning are still being developed. LLM’s themselves can be used to assist with the generation of training data, but this may take some sophistication to be effective.
The Solution, Simplified
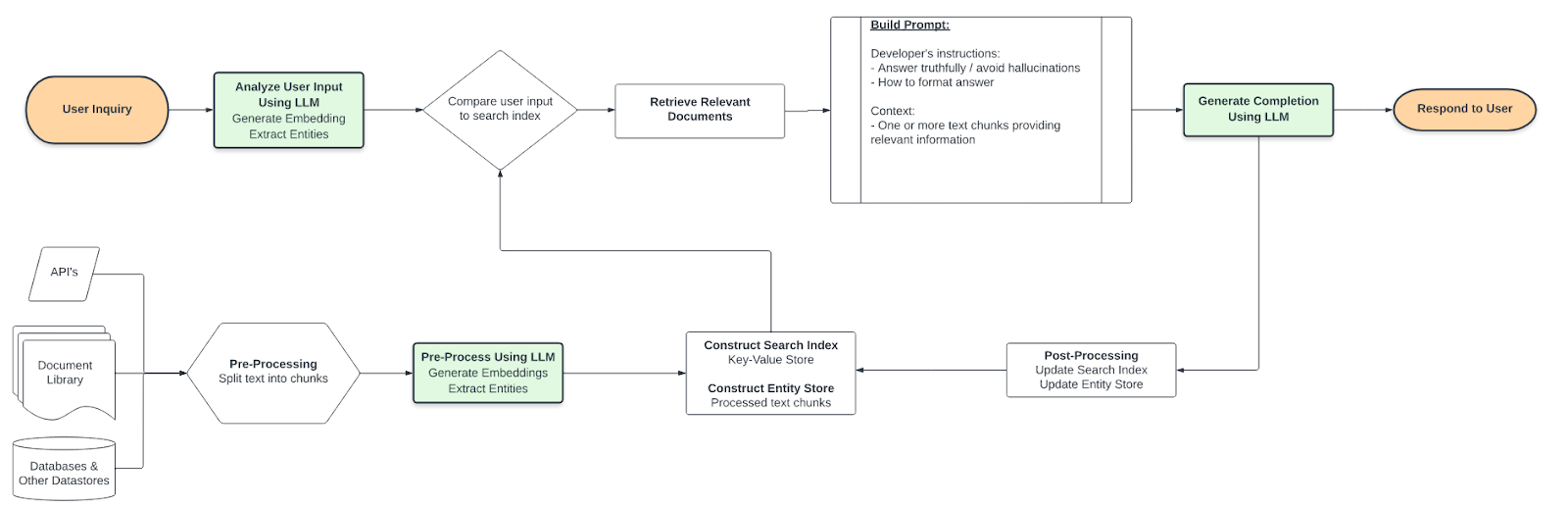
The design above goes by various names, most commonly “retrieval-augmented generation” or “RETRO”. Links & related concepts:
- RAG: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- RETRO: Improving language models by retrieving from trillions of tokens
- REALM: Retrieval-Augmented Language Model Pre-Training
Retrieval-augmented generation a) retrieves relevant data from outside of the language model (non-parametric) and b) augments the data with context in the prompt to the LLM. The architecture cleanly routes around most of the limitations of fine-tuning and context-only approaches.
Retrieval

The retrieval of relevant information is worth further explanation. As you can see, data may come from multiple sources depending on the use case. In order for the data to be useful, it must be sized small enough for multiple pieces to fit into context and there must be some way to identify relevance. So a typical prerequisite is to split text into sections (for example, via utilities in the LangChain package), then calculate embeddings on those chunks.
Language model embeddings are numerical representations of concepts in text and seem to have