



I’m a journalist with a computer science master’s degree. In the past I’ve written for the Washington Post, Ars Technica, and other publications.
This is the first edition of my newsletter, Understanding AI. It will explore how AI works and how it’s changing the world. If you like it, please sign up to have future articles sent straight to your inbox.
The AI software Stable Diffusion has a remarkable ability to turn text into images. When I asked the software to draw “Mickey Mouse in front of a McDonalds sign,” for example, it generated the picture you see above.
Stable Diffusion can do this because it was trained with hundreds of millions of example images harvested from across the web. Some of these images were in the public domain or had been published under permissive licenses such as Creative Commons. Many others were not—and the world’s artists and photographers aren’t happy about it.
In January, three visual artists filed a class-action copyright lawsuit against Stability AI, the startup that created Stable Diffusion. In February, the image licensing giant Getty filed a lawsuit of its own.
“Stability AI has copied more than 12 million photographs from Getty Images’ collection, along with the associated captions and metadata, without permission from or compensation to Getty Images,” Getty wrote in its lawsuit.
Legal experts tell me that these are uncharted legal waters.
“I’m more unsettled than I’ve ever been about whether training is fair use in cases where AIs are producing outputs that could compete with the input they were trained on,” the Cornell legal scholar James Grimmelmann told me.
Generative AI is such a new technology that the courts have never ruled on its copyright implications. There are some strong arguments that copyright’s fair use doctrine allows Stability AI to use the images. But there are also strong arguments on the other side. There’s a real possibility that the courts could decide that Stability AI violated copyright law on a massive scale.
That would be a legal earthquake for this still nascent industry. Building cutting-edge generative AI would require getting licenses from thousands, perhaps even millions, of copyright holders. The process would likely be so slow and expensive that only a handful of large companies could afford to do it. Even then, the resulting models likely wouldn’t be as good. And smaller companies might be locked out of the industry altogether.
The plaintiffs in the class-action lawsuit describe Stable Diffusion as a “complex collage tool” that contains “compressed copies” of its training images. If this were true, the case would be a slam dunk for the plaintiffs.
But experts say it’s not true. Erik Wallace, a computer scientist at the University of California, told me in a phone interview that the lawsuit had “technical inaccuracies” and was “stretching the truth a lot.” Wallace pointed out that Stable Diffusion is only a few gigabytes in size—far too small to contain compressed copies of all or even very many of its training images.
In reality, Stable Diffusion works by first converting a user’s prompt into a latent representation: a list of numbers summarizing the contents of the image. Just as you can identify a point on the earth’s surface based on its latitude and longitude, Stable Diffusion characterizes images based on their “coordinates” in the “picture space.” It then converts this latent representation into an image.
Let’s make this concrete by looking at an example from this excellent article about Stable Diffusion’s latent space:
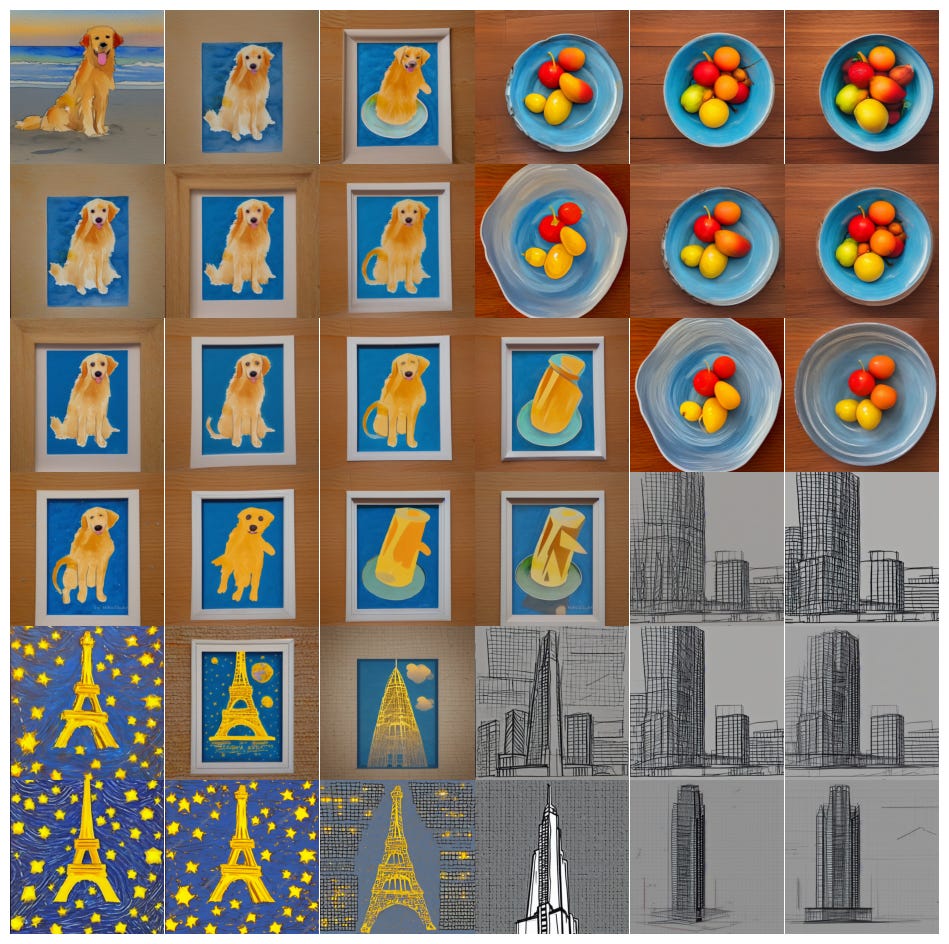
If you ask Stable Diffusion to draw “a watercolor painting of a Golden Retriever at the beach,” it will produce a picture like the one in the upper-left corner of this image. To do this, it first converts the prompt to a corresponding latent representation—that is, a list of numbers summarizing the elements that are supposed to be in the picture. Maybe a positive value in the 17th position indicates a dog, a negative number in the 54th position represents a beach, a positive value in the 73rd position means a water-color painting, and so forth.
I just made those numbers up for illustrative purposes; the real latent representation is more complicated and not easy for humans to interpret. But in any event there will be a list of numbers that correspond to the prompt, and Stable Diffusion uses this latent representation to generate an image.
The pictures in the other three corners were also generated by Stable Diffusion using the following prompts:
-
Upper right: “a still life DSLR photo of a bowl of fruit”
-
Lower left: “the eiffel tower in the style of starry night”
-
Lower right: “an architectural sketch of a skyscraper”
The point of the six-by-six grid is to illustrate that Stable Diffusion’s latent space is continuous: the software can not only draw an image of a dog or a bowl of fruit, it can also draw images that are “in between” a dog and a bowl of fruit. The third picture on the top row, for example, depicts a slightly fruit-looking dog sitting on a blue dish.
Or look along the bottom row. As you move from left to right, the shape of the building gradually changes from the Eiffel Tower to a skyscraper, while the style changes from a Van Gogh painting to an architectural sketch.
The continuous nature of Stable Diffusion’s latent space enables the software to generate latent representations—and hence images—for concepts that were not in its training data. There probably wasn’t an “Eiffel Tower drawn in the style of ‘Starry Night’” image in Stable Diffusion’s training set. But there were many images of the Eiffel Tower and, separately, many images of “Starry Night.” Stable Diffusion learned from these images and was then able to produce an image that reflected both concepts.
How does Stable Diffusion learn to do this? A novice painter might go to an art museum and try to make exact copies of famous paintings. The first few attempts won’t be very good, but she’ll get a little better with each attempt. If she keeps at it long enough, she’ll master the styles and techniques of the paintings she copies.
The process for training an image-generation network like Stable Diffusion is similar, except that it happens at a vastly larger scale. The training process uses a pair of networks designed to first map an image into latent space and the