


I gave a talk on Sunday at North Bay Python where I attempted to summarize the last few years of development in the space of LLMs—Large Language Models, the technology behind tools like ChatGPT, Google Bard and Llama 2.
My goal was to help people who haven’t been completely immersed in this space catch up to what’s been going on. I cover a lot of ground: What they are, what you can use them for, what you can build on them, how they’re trained and some of the many challenges involved in using them safely, effectively and ethically.
- What they are
- How they work
- A brief timeline
- What are the really good ones
- Tips for using them
- Using them for code
- What can we build with them?
- ChatGPT Plugins
- ChatGPT Code Interpreter
- How they’re trained
- Openly licensed models
- My LLM utility
- Prompt injection
The video for the talk is now available, and I’ve put together a comprehensive written version, with annotated slides and extra notes and links.
Read on for the slides, notes and transcript.

I’m going to try and give you the last few years of LLMs developments in 35 minutes. This is impossible, so hopefully I’ll at least give you a flavor of some of the weirder corners of the space.
- simonwillison.net is my blog
- fedi.simonwillison.net/@simon on Mastodon
- @simonw on Twitter

The thing about language models is the more I look at them, the more I think that they’re fractally interesting. Focus on any particular aspect, zoom in and there are just more questions, more unknowns and more interesting things to get into.
Lots of aspects are deeply disturbing and unethical, lots are fascinating. It’s impossible to tear myself away.

Let’s talk about what a large language model is.
One way to think about it is that about 3 years ago, aliens landed on Earth. They handed over a USB stick and then disappeared. Since then we’ve been poking the thing they gave us with a stick, trying to figure out what it does and how it works.

This is a MidJourney image—you should always share your prompts. I said “Black background illustration alien UFO delivering thumb drive by beam.” It didn’t give me that, but that’s somewhat representative of this entire field—it’s rare to get exactly what you ask for.
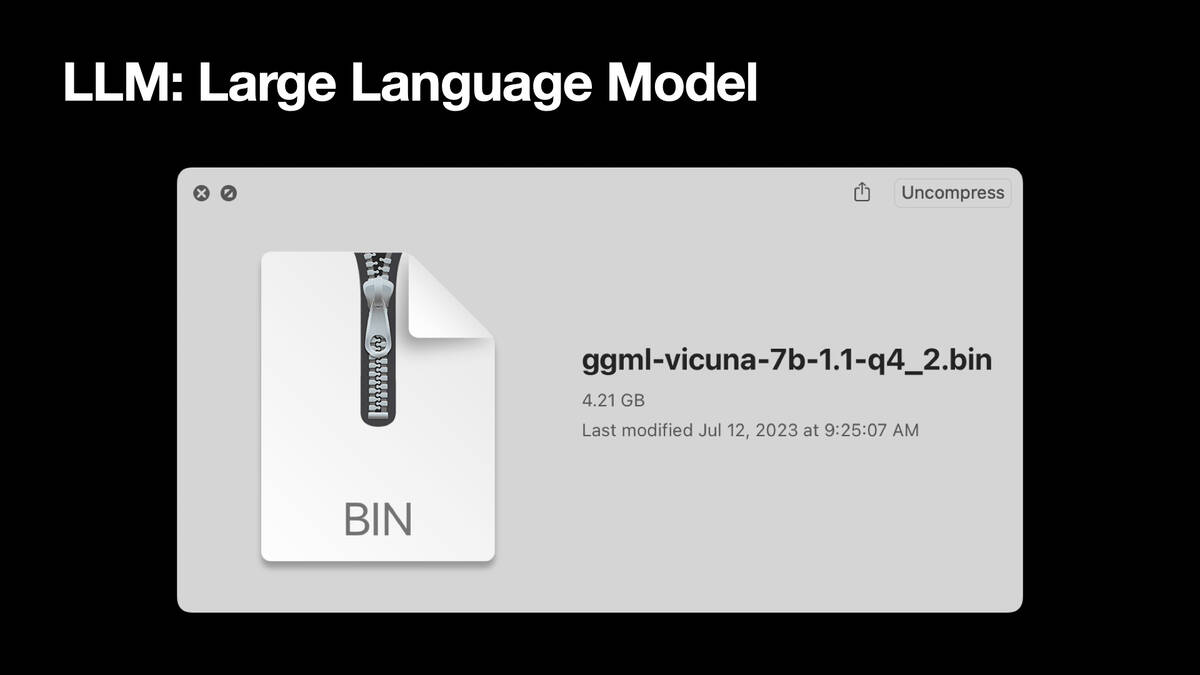
A more practical answer is that it’s a file. This right here is a large language model, called Vicuna 7B. It’s a 4.2 gigabyte file on my computer. If you open the file, it’s just numbers. These things are giant binary blobs of numbers. Anything you do with them involves vast amounts of matrix multiplication, that’s it. An opaque blob that can do weird and interesting things.
LLM Python library with the llm-gpt4all plugin installed in order to run the Vicuna 7B model packaged by GPT4All—as described in My LLM CLI tool now supports self-hosted language models via plugins.)

A sea otter, with its fluffy fur and playful nature,
Enjoys the ocean’s bounty as it munches on some kelp.
Its paws are nimble as they scoop up delicious treats,
While its eyes sparkle with joy at this brunch feat.
A sea otter