


Yes, DeepSeek is impressive.
But the buzz around DeepSeek is potentially more impressive – not since GPT4 have I seen a single AI model take the entire world by storm. Rarely in my life have I seen as many bad takes. It’s time to go through some of the hype and set the record straight.
DeepSeek is impressive, but it is not some crazy unexpected outlier. DeepSeek is cheap but not actually amazingly cheap. Most importantly, DeepSeek is not the end of US export controls or US AI dominance, and it does not challenge our understanding of geopolitics nearly as much as you might think if you only read the headlines.
Let’s dive in and give it a fairer assessment.
First off the bat, I am not a DeepSeek denier or a DeepSeek doubter. I do want to acknowledge that DeepSeek is truly impressive. There are some genuine innovations:
-
Multi-head latent attention (MLA) for efficient memory usage, reducing the size of model without compromising quality by using a cool compression technique.
-
Improved mixture-of-experts (MoE) architecture, increasing load balancing to better handle the balance between common and specialized knowledge.
-
More token-efficient training by using formulas “predict” which tokens the model would activate and training on only those tokens, thus needing fewer GPUs by training fewer parameters.
-
Multi-token prediction capabilities, which allows the model to predict two tokens ahead with 85-90% accuracy, potentially doubling inference speed.
-
V3’s training uses mixed-precision FP8 arithmetic and advanced load-balancing tweaks to further improve speed
These improvements demonstrate deep understanding of Transformer architecture limitations rather than brute-force experimentation. The fact that the service is being offered for free with no plans for commercialization is impressive and it does genuinely broaden people’s access to a strong reasoning model.
Lastly, sharing all of these innovations in an open access way with open weights will be a large improvement to research. For example, R1 already taught us that it appears making a reasoning model does not need fancy techniques like process reward or Monte Carlo Tree Search and instead you can just use the simplest approach: ‘guess and check’ (produce a candidate answer, or ‘guess’, and then run it through a verification process, the ‘check’, and adjust from there).
People who are just tuning into DeepSeek recently have missed a trend that they could’ve seen coming.
DeepSeek is owned by High-Flyer, a Chinese hedge fund that trades exclusively with AI. They pivoted more into AI in 2023. Since then, DeepSeek has clearly been the best Chinese AI lab. DeepSeek first published some of their innovations in MoE in 2024 January already showing good efficiency gains, being more efficient than Meta’s Llama model. DeepSeek-V2 in 2024 May showed their innovations in MLA. SemiAnalysis also reported on DeepSeek as early as May.
From the above, it was easy to extrapolate what might come out, but to top it off the DeepSeek-V3 paper that proved it all came out in 2024 December 27, almost a full month before people started freaking out about DeepSeek.
DeepSeek v3 was trained for $6M. OpenAI Stargate is spending $100B per year – more than 15,000 times the DeepSeek v3 price tag. But OpenAI models don’t seem that much better. What’s going on here?
The answer is you’re comparing incorrectly.
The “$6M” figure refers to the marginal cost of the single pre-training run that produced the final model. But there’s much more that goes into the model – cost of infrastructure, data centers, energy, talent, running inference, prototyping, etc. Usually the cost of the single training run for the single final model training run is ~1% of the total capex spent developing the model.
It’s like comparing the marginal cost of treating a single sick patient in China to the total cost of building an entire hospital in the US.
For example, per SemiAnalysis, DeepSeek apparently has a GPU fleet of ~10K A100 NVIDIA GPUs and ~10K H100s acquired prior to the US-led export controls that banned exports of these in October 2022 plus another ~10K H800s (which are nearly as good as H100s and were export controlled in October 2023). On top of that, DeepSeek likely has another ~20K H20s, which are not as good as H100s/H800s/A100s and are not under export controls. At a market price of ~$15K/GPU on average, this would cost $750M just for GPUs.
SemiAnalysis calculates the total server capex for DeepSeek at ~$1.6B.
…Then there were 199 ML researchers on the v3 technical paper. Even given that Chinese salaries are much lower, DeepSeek still pays well and is still rumored to pay salaries above $1M USD/yr to top candidates. Even if we assume the average salary of their paper team is $300K/person/year, that means the staff costs alone are ~$60M/yr.
Lastly, the DeepSeek r1 model that is being compared to OpenAI’s models is a reasoning model trained on top of DeepSeek v3 (similar to how OpenAI o1 is a reasoning model on top of the base model of GPT4o) and training this reasoning model likely took another few million in compute. People quoting that DeepSeek r1 was trained with $6M are thus being doubly misleading by not including the costs of developing the reasoning model – in addition to not mentioning the capex not related to immediately training the final model.
The bull case for DeepSeek is that it is as good as or better than o1 despite being much cheaper. However, this doesn’t seem to be the case.
Cost: Not the cheapest
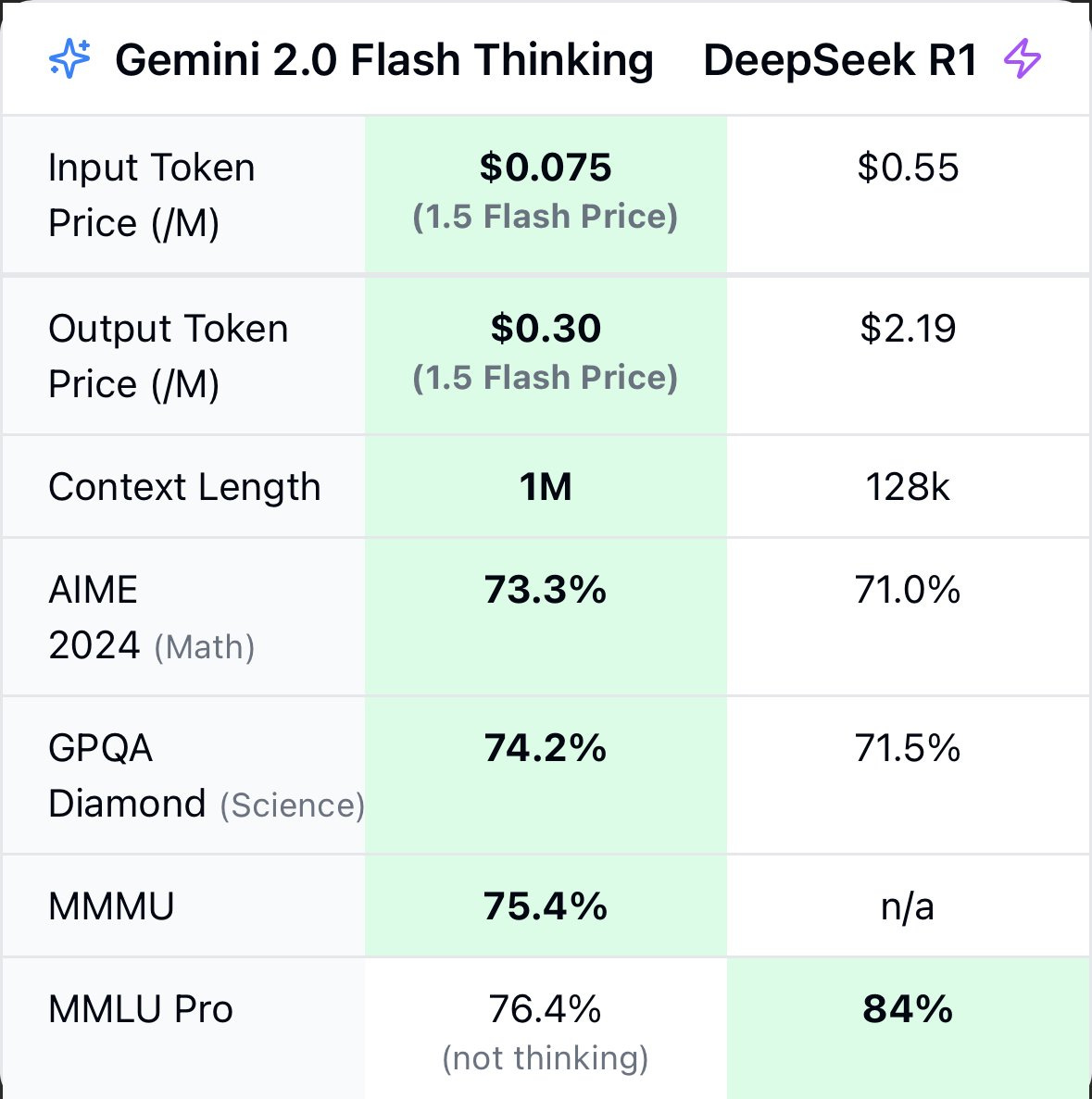
Almost all DeepSeek takes seem premised on the idea that Gemini 2.0 Flash Thinking (G2FT) doesn’t exist. DeepSeek r1 is not the first model to show the chain of thought to the user, G2FT is! Also while r1 at $2.19 per million output tokens is very cheap, it is not as cheap as G2FT – G2FT will likely be available for almost 10x cheaper at $0.30 per million output tokens. (The fact that people don’t know this shows that Google is bad at marketing.)
Furthermore, this comparison for price isn’t necessarily apples-to-apples. When comparing costs between models, we have to take into account profit margins. My guess is that DeepSeek is not offering their model with much of a profit margin, whereas we don’t know how much of a profit margin is baked into Google or OpenAI’s offerings. Additionally, it seems that r1 uses more chain-of-thought tokens (which you still pay for), and if you don’t care about those and just want the final output, it may be even less cheap in comparison than you expect.
Performance: Not the best
While R1 is good, R1 is not the best reasoning model either (even on questions not related to Tiananmen Square). From my personal testing it seems a touch worse than OpenAI o1 and definitely worse than OpenAI o1-pro (the $200/month version). And I imagine o3 will be even better.
In fact, r1 even loses to the cheaper G2FT on some benchmarks, though I think r1 is better overall.
Timothy B. Lee from Understanding AI puts OpenAI o1-pro, Gemini 2.0 Flash Thinking, and DeepSeek r1 throu