


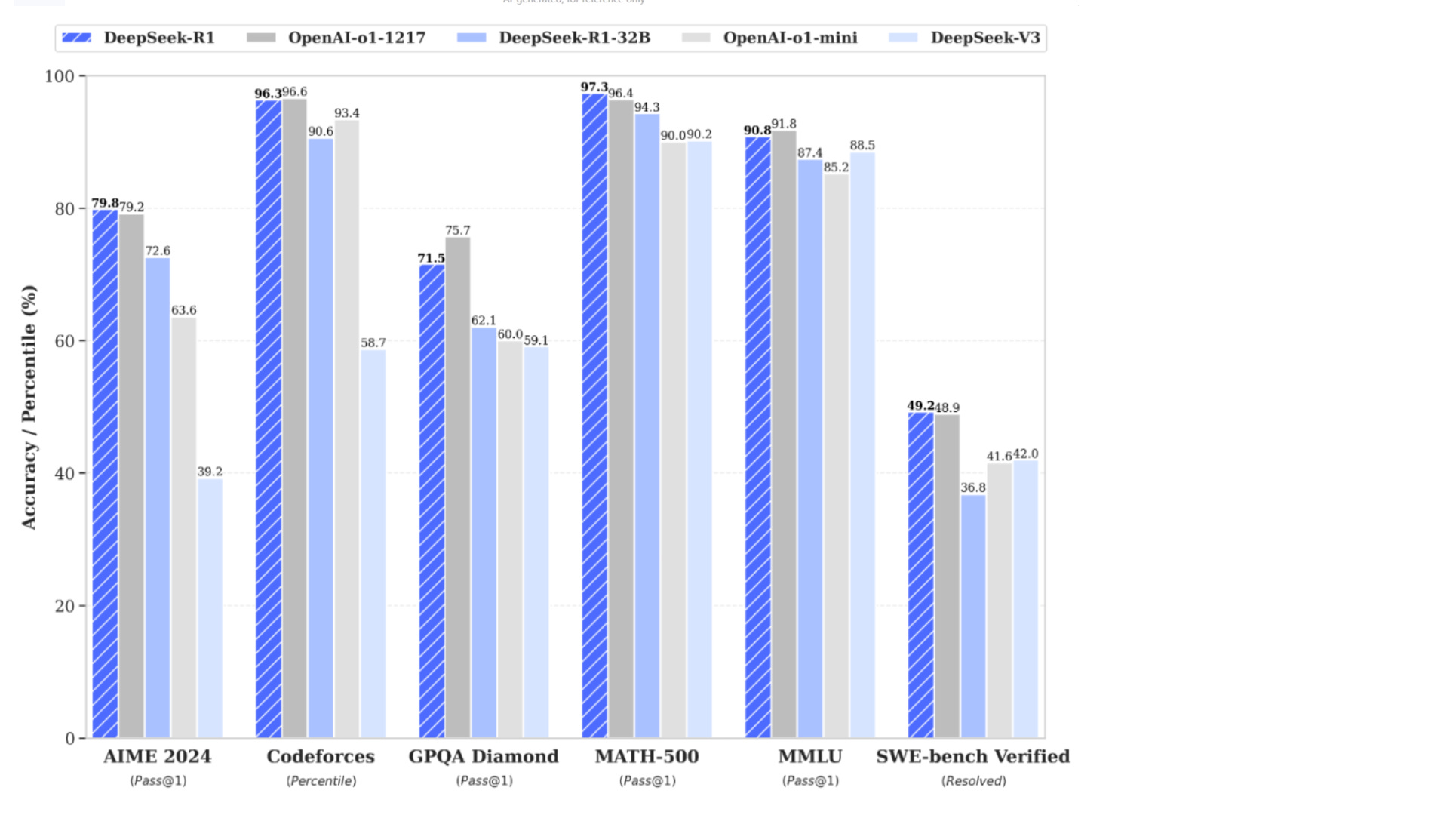
TL;DR for this article: DeepSeek was certain to happen. The only unknown was who was going to do it. The choices were a startup or someone outside the current center of leadership and innovation in AI, which is mostly in the US clustered around trillion-dollar companies. It turned out to be a group in China, which for many (me too) is unfortunate. But again, it absolutely was going to happen. The next question is will the US makers see this with clarity.
There’s more in The Short Case for Nvidia Stock which is very good but focuses on picking stocks, which isn’t my thing. Strategy and execution are more me so here’s that perspective.
The current trajectory of AI if you read the news in the US is one of MASSIVE CapEx piled on top of even more MASSIVE CapEx. It is a race between Google, Meta, OpenAI/Microsoft, xAI, and to a lesser extent a few other super well-funded startups like Perplexity and Anthropic. All of these together are taking the same approach which I will call “scale up”. Scale up is what you do when you have access to vast resources as all of these companies do.
The history of computing is one of innovation followed by scale up which is that broken by a model that “scales out”—when a bigger and faster approach is replaced by a smaller and more numerous approaches. Mainframe->Mini->Micro->Mobile, Big iron->Distributed computing->Internet, Cray->HPC->Intel/CISC->ARM/RISC, OS/360->VMS->Unix->Windows NT->Linux, and on and on. You can see this at these macro levels, or you can see it at the micro level when it comes to subsystems from networking to storage to memory.
The past 5 years of AI have been bigger models, more data, more compute, and so on. Why? Because I would argue the innovation was driven by the cloud hyperscale companies and they were destined to take the approach of doing more of what they already did. They viewed data for training and huge models as their way of winning and their unique architectural approach. The fact that other startups took a similar approach is just Silicon Valley at work—the people move and optimize for different things at a micro scale without considering the larger picture. They look to do what they couldn’t do at their previous efforts or what the previous efforts might have been overlooking.
The degree to which the hyperscalers believed in Scale Up is obvious when you look at all of them building their own Silicon. As cool as this sounds, it has historically proven very very difficult for software companies to build their own silicon. While many look at Apple as a success, Apple’s lessons emerged over decades of not succeeding PLUS they build a device not just silicon. Apple learned from 68k, PPC, Intel, how to optimize a design for their scenarios. Those building AI hardware were solving their in-house scale up challenges—I would have always argued they could gain percentages at a constant factor but not anything beyond that.
Nvidia is there to help everyone not building their own silicon and those that wish to build their own silicon but are also trying to meet immediately needs. As described in “The Short Case” Nvidia also has a huge software ecosystem advantage with CUDA, something they have honed for almost two decades. It is critically important to have an ecosystem, and they have been successful at that. This is why I wrote and thought the DIGITS project is far more interesting than simply a 4000 TOPS desktop (see my CES report).
So now where are we? Well, the big problem we have is that the big scale solutions, no matter all the progress, are consuming too much capital. But beyond that the delivery to customers has been on an unsustainable path. It is a path that works against the history of computing, which is that resources needed become free, not more expensive. The market for computing simply doesn’t accept solutions that cost more, especiall