


Introduction
In this article, we are going to see what UUID (Universally Unique Identifier) type works best for a database column that has a Primary Key constraint.
While the standard 128-bit random UUID is a very popular choice, you’ll see that this is a terrible fit for a database Primary Key column.
Standard UUID and database Primary Key
A universally unique identifier (UUID) is a 128-bit pseudo-random sequence that can be generated independently without the need for a single centralized system in charge of ensuring the identifier’s uniqueness.
The RFC 4122 specification defines five standardized versions of UUID, which are implemented by various database functions or programming languages.
For instance, the UUID() MySQL function returns a version 1 UUID number.
And the Java UUID.randomUUID() function returns a version 4 UUID number.
For many devs, using these standard UUIDs as a database identifier is very appealing because:
- The ids can be generated by the application. Hence no central coordination is required.
- The chance of identifier collision is extremely low.
- The id value being random, you can safely send it to the UI as the user would not be able to guess other identifier values and use them to see other people’s data.
But, using a random UUID as a database table Primary Key is a bad idea for multiple reasons.
First, the UUID is huge. Every single record will need 16 bytes for the database identifier, and this impacts all associated Foreign Key columns as well.
Second, the Primary Key column usually has an associated B+Tree index to speed up lookups or joins, and B+Tree indexes store data in sorted order.
However, indexing random values using B+Tree causes a lot of problems:
- Index pages will have a very low fill factor because the values come randomly. So, a page of 8kB will end up storing just a few elements, therefore wasting a lot of space, both on the disk and in the database memory, as index pages could be cached in the Buffer Pool.
- Because the B+Tree index needs to rebalance itself in order to maintain its equidistant tree structure, the random key values will cause more index page splits and merges as there is no pre-determined order of filling the tree structure.
If you’re using SQL Server or MySQL, then it’s even worse because the entire table is basically a clustered index.
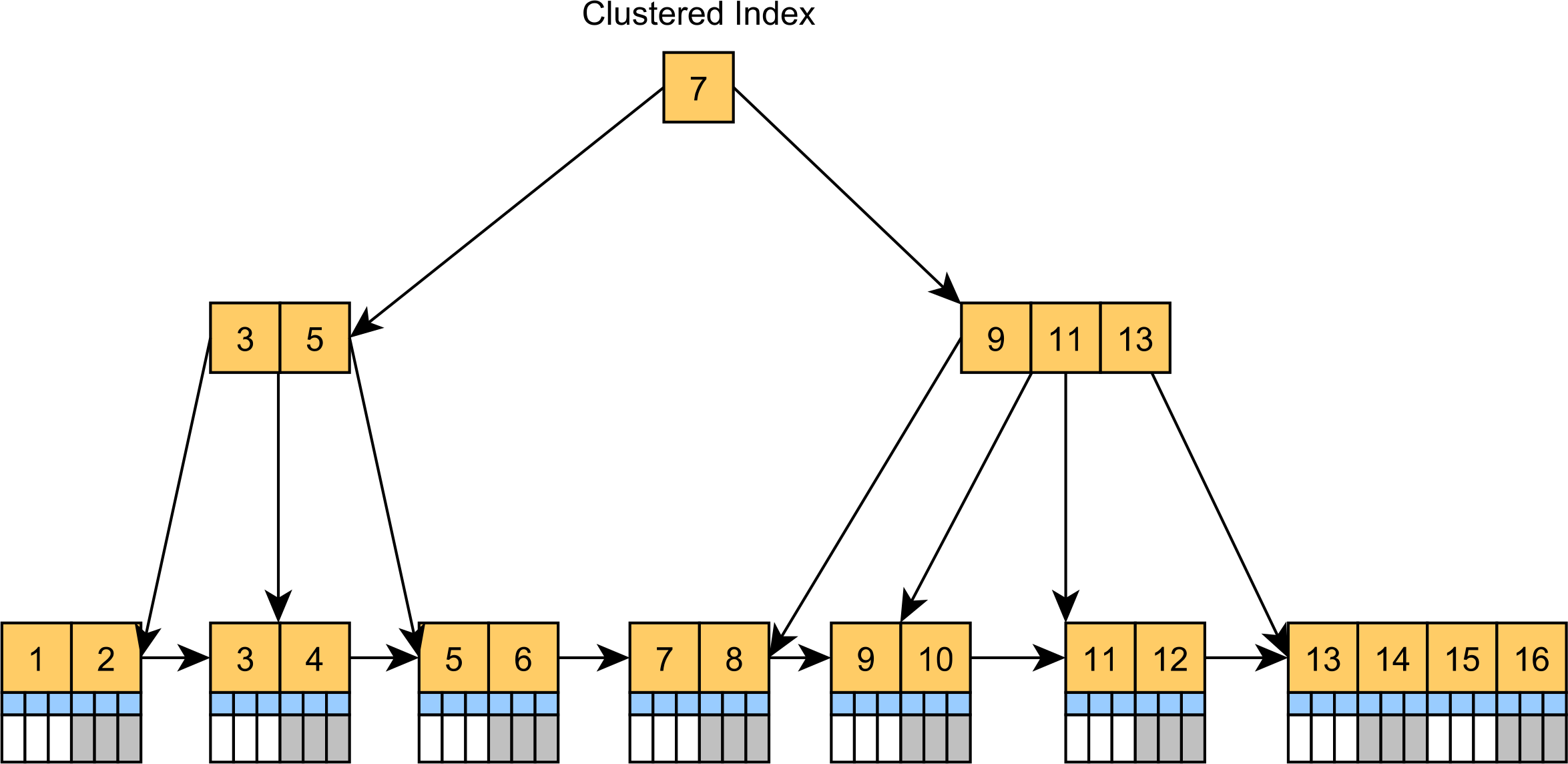
And all these problems will affect the secondary indexes as well because they store the Primary Key value in the secondary index leaf nodes.

In fact, almost any database expert will tell you to avoid using the standard UUIDs as database table Primary Keys:
- Percona: UUIDs are Popular, but Bad for Performance
- UUID or GUID as Primary Keys? Be Careful!
- Identity Crisis: Sequence v. UUID as Primary Key
TSID – Time-Sorted Unique Identifiers
If you plan to store UUID values in a Primary Key column, then you are better off using a TSID (time-sorted unique identifier).
One such implementation is offered by the Hypersistence TSID OSS library, which provides a 64-bit TSID that’s made of two parts:
- a 42-bit time component
- a 22-bit random component
The random component has two parts:
- a node identifier (0 to 20 bits)
- a counter (2 to 22 bits)
The node identifier can be provided by the tsid.node system property when bootstrapping the application:
-Dtsid.node="12"
The node identifier can also be provided via the TSID_NODE environment variable:
export TSID_NODE="12"
The library is available on Maven Central, so you can get it via the following dependency:
io.hypersistence hypersistence-tsid ${hypersistence-tsid.version}
You can create a TSID object like this:
TSID tsid = TSID.fast();
From the Tsid object, we can extract the following values:
- the 64-bit numerical value,
- the Crockford’s Base32 String value that encodes the 64-bit value,
- the Unix milliseconds since epoch that is stored in the
42-bit sequence
To visualize these values, we can print them into the log:
long tsidLong = tsid.toLong();
String tsidString = tsid.toString();
long tsidMillis = tsid.getUnixMilliseconds();
LOGGER.info(
"TSID numerical value: {}",
tsidLong
);
LOGGER.info(
"TSID string value: {}",
tsidString
);
LOGGER.info(
"TSID time millis since epoch value: {}",
tsidMillis
);
And we get the following output:
TSID numerical value: 470157774998054993 TSID string value: 0D1JP05FJBA2H TSID time millis since epoch value: 1689931148668
When generating ten values:
for (int i = 0; i < 10; i++) {
LOGGER.info(
"TSID numerical value: {}",
TSID.fast().toLong()
);
}
We can see that the values are monotonically increasing:
TSID numerical value: 470157775044192338 TSID numerical value: 470157775044192339 TSID numerical value: 470157775044192340 TSID numerical value: 470157775044192341 TSID numerical value: 470157775044192342 TSID numerical value: 470157775044192343 TSID numerical value: 470157775044192344 TSID numerical value: 470157775048386649 TSID numerical value: 470157775048386650 TSID numerical value: 470157775048386651
Awesome, right?
Using the TSID in your application
Because the default TSID factories come with a synchronized random value generator, it’s better to use a custom TsidFactory that provides the following optimi