


I’ve been working on general purpose robots with Everyday Robots for 8 years, and was the engineering lead of the product/applications group until we were impacted
by the recent Alphabet layoffs. This series is an attempt to share almost a decade of lessons learned so you can get a head start making robots that live and work among us. Previous posts live here.
This post is going to be about some tips and tricks to make robot application code cleaner and easier to read. It’s going to be example heavy, so if programming ain’t your thing, you might want to skip this one.
Programming is programming and best practices from other domains mostly work out well. However there are a few things about robots that create unique challenges. But let’s start with a concrete example. We’ll be working with this code snippet to make a robot pour tea:
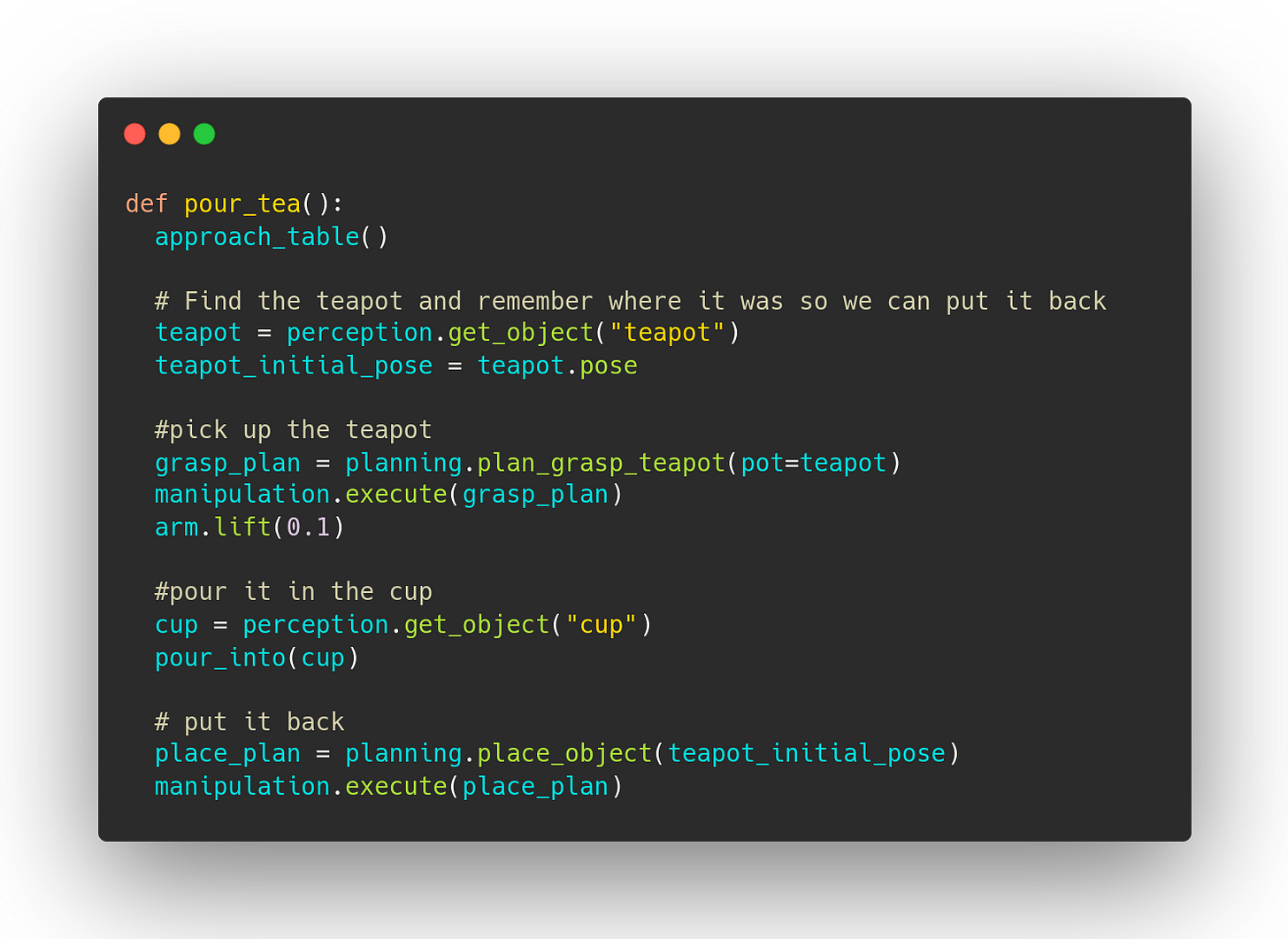
This code looks pretty nice. It’s only 20 lines and it tells the story of what’s happening. Unfortunately, with robots, nearly every method interacts with the world outside the computer and can fail.
Planning can fail because there is no way to get to the goal, or the robot would collide on the way or because it’s out of reach, or just because the algorithm failed to find a solution before the timeout.
Motion can fail because we detect an unexpected collision or fail to track our trajectory or have a hardware failure.
Finding objects in the world can fail because our Neural Networks fail or because the objects aren’t actually there or because they’re hidden behind something.
And if “step three” of your plan fails you usually don’t want to (or can’t) go on to execute steps four, five and six.
So we’re going to make a very common choice: we’re going to say that motion commands will return a True if the command was successfully executed and False if it fails.
This reasonable seeming choice is going to bite us in the butt. To see why, let’s use these success bools to add some error handling where it’s needed.
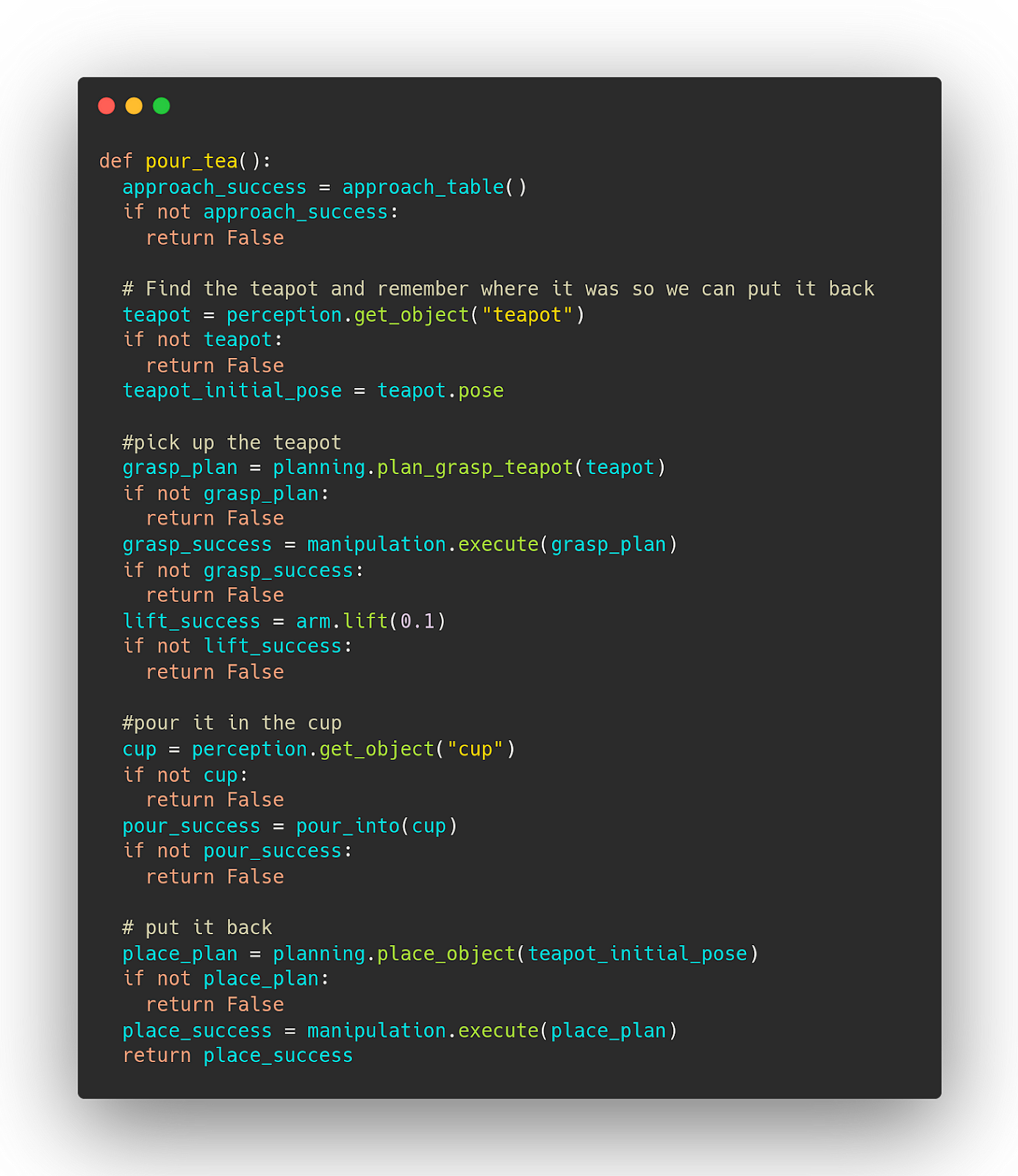
This has already ballooned quite a bit and I find it harder to follow the action. You can do cute tricks like replacing:

with something like

but I get a gross feeling in my tummy putting big, robot-moving calls inside the predicates of if statements.
So if you try and run this you will immediately learn an important rule in robotics: log everything.
You will run this method, the robot will approach the table and then it will return False. You don’t know what’s wrong. Did it fail to see the teapot? Plan the grasp? Fail right at the start of executing the grasp? You add a breakpoint and rerun, but the robot executes the whole thing through perfectly that time (of course).
You need logging because the world is a giant hairy ball of unobservable global state and it makes reproducing errors really hard. Let’s add some logging so we know what’s happening.
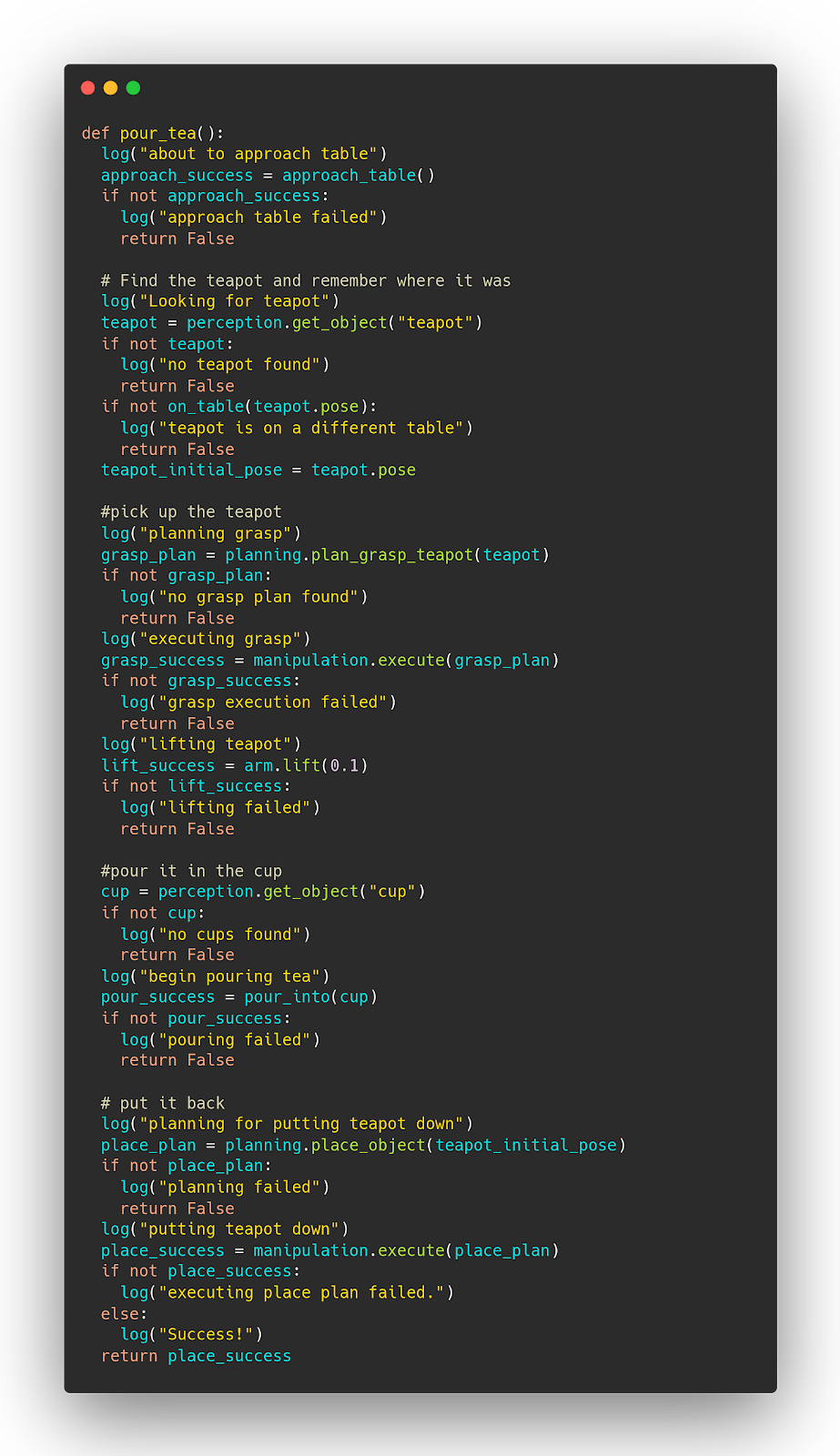
The logs will now tell us what’s wrong (and give a timestamp to match to a logged video or internal robot state log):

Ahah! We don’t see the cups… I wonder why? Now you know what to fix. Hooray for logging.
But the code is gross. It’s 3x as long as it was and I can’t even see the whole method on my laptop screen without scrolling. The actual business logic is buried by all the logging and error handling. All of our application code at Everyday Robots used to look like this, and it was hard to deal with because it was just hard to read. You want as much of your brain dedicated to solving your hard problems, not wasted trying to find the logic in a sea of cruft. We’re going to make two changes so that this code can look like the first block but behave like this last one.
The first thing we’re going to do is get rid of boolean success returns.
Boolean success returns are bad.
Not just because they encourage code like that last listing, but because they make a very strong assumption that there is only one way to succeed and one way to fail. Both of those are often wrong! If you collide on the way to a goal you want the robot to do a different thing than if the motor is in fault. But both of those are just “False” from manipulation.execute. If you return success booleans you are setting yourself up for a painful refactor in your future. We had good luck using enums when we cared about different kinds of success, but when we cared about success vs failure they come with the same krufty verbosity.
So to represent failures, I recommend raising subclasses of your own exception type. Like this:
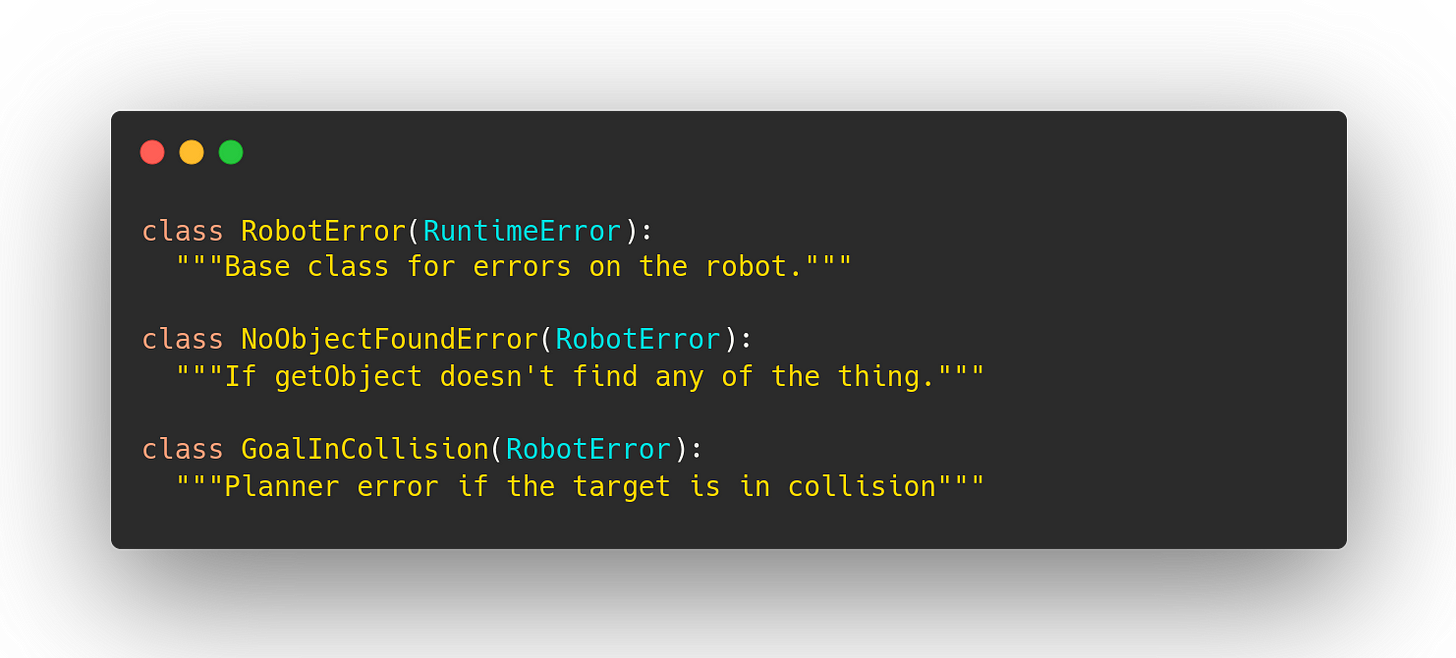
This buys you four things.
-
You get the behavior you wanted: If step 2 fails we don’t move on to step 3. And you get it by default, meaning that silently forgetting to handle a potential error is no longer a bug your API lets you write.
-
Failures are bubbled up by default instead of needing to remember to log them.
-
It lets you pick what kinds of failures you want to deal with at what scope.
-
Flexibility: If you’re raising and then catching a PlanningError and later decide you care about different ways the planner could fail, you can have plan() raise different subclasses of PlanningError and call sites can catch all PlanningErrors or just the subclasses they care about without you needing to refactor any code in between.
The other change we’ll make is to create a python decorator that logs whenever we enter and exit particular methods. You don’t want to have this on every method, especially something you might be doing in a fast loop (because there are some performance implications and you don’t want to spam your text logs), but at this level of the stack our methods often take many seconds to execute anyway (because we are waiting for hardware to move around) so time spent logging gets lost in the noise. I’ve written a version here.
We’ll put it on all